
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- EDA
- Datascientist
- IT멘토링
- 모델링
- 삼성sds
- 데이터전처리
- 삼성자격증
- 골목상권데이터분석
- kaggle
- SDSBrightics
- 브라이틱스서포터즈
- Kaggle출전
- houseprice
- BrighticsStudio
- 삼성SDSBrightics
- Brightics
- 브라이틱스
- 서울시상권분석
- samsungsds
- 분석모델링
- AdSP
- 데이터분석
- 브라이틱스데이터분석
- 상권배후지
- 코딩없이데이터분석
- associateDS
- 데이터분석대외활동
- 회귀모형평가
- Brightics서포터즈
- ProDS
- Today
- Total
Database for Everything
[삼성 SDS Brightics] 차이 검정① - Paired T-test, Independent T-test 본문
[삼성 SDS Brightics] 차이 검정① - Paired T-test, Independent T-test
Yeenn 2021. 6. 24. 16:54
안녕하세요!
벌써 브라이틱스 개인분석실습 3주차에 접어들었네요.
(시간이 너무 빨리가네요..)
종강도 했겠다.. 브라이틱스 활동에 더 많이 집중할 수 있는 시간이 생겨서 기쁩니다ㅎㅎ
이번 Brightics 실습에서 다룰 주제는
"T검정" 입니다!
T 검정이란?
T검정, T-test는 두 집단간의 평균을 비교하는 모수적 통계방법으로서, 표본이 정규성, 등분산성, 독립성 등을 만족할 경우 적용이 가능한 검정 방법입니다.
| 항목 | 설명 |
| 독립성 | 관측치는 각각 독립이다. 관측치는 서로 영향을 주지 않는다. |
| 정규성 | 두 그룹의 모집단은 각각 정규분포이다. |
| 등분산성 | 두 그룹의 분산은 동일하다. |
이번 포스팅에서 다룰 T검정은 Paired T-test와 Independent T-test인데요, 본격적인 실습과 설명에 들어가기 전,
두 T 검정의 table 구성을 통해 두 검정방법을 간단히 비교해보도록 하겠습니다.
[Paired T-test]
Paired T-test는 서로 짝을 이루어 비교하는 경우에 쓰이는 검정방법인데요, 아래의 table의경우 ID값을 기준으로 Treatment A와 Treatment B의 변화량이 짝지어져 비교되어있는 것을 확인할 수 있습니다.

[Independent T-test]
Independent T-test는 비교하는 두 군이 서로 독립인 경우에 쓰이는 검정방법인데요, 아래의 table의경우 Treatment A와 Treatment B가 독립적이므로 A와 B의 독립적으로 비교되어있는 것을 확인할 수 있습니다.

두 T검정의 차이점에 대한 감이 오시나요?
다음 Brightics실습을 통해 더욱 Paired T-test와 Independent T-test애 대해 더욱 자세히 알아보도록 하겠습니다!
두 실습 모두 아래와 같은 동일한 dataset을 활용할 예정입니다.
Dataset 변수 구성
A, B 대리점의 일시 별 매출액과 프로모션 여부 데이터 shop_ab_sales.csv
| 변수명 | 설명 |
| pos_date | pos 날짜(판매 날짜) |
| post_hour | pos 시간(판매 기간) |
| date_hour | pos 날짜와 시간(판매 일시) |
| shop_nm | 대리점명 |
| sales_amt | 판매금액 |
| prom_yn | 프로모션 기간여부(프로모션 수행은 A대리점만) |
[짝지어진 T검정 Paired T-test 실습]
Paired T-test는 두 표본의 각 값에 대해 짝을 지어 그 차이의 평균이 특정한 값인지 아닌지, 그 값보다 작은지 또는 같은지를 검정하는 방법인데요, 대응되는 표본이 있어야 검정이 가능합니다.
1) 상황: A 대리점은 제품의 판매량을 늘리기 위해 일정기간 프로모션을 수행하였으나, B 대리점은 프로모션을 수행하지 않았다.
2) 실습 목표: A 대리점이 프로모션을 하지 않은 경쟁 B 대리점 대비 매출이 증가하였는지 비교하고자 한다. (매출액이 유의미하게 증가하였는지 파악한다.)
→ 프로모션을 할 때는 A, B 대리점의 매출액 차이가 유의한지 확인하기 위해 프로모션 여부별 짝지어진 paired t-test를 수행한다.
3) 귀무가설 H0: 각 일시별 A, B 대리점 매출액 차이는 없다.
0. Data Flow Model 구성

paired t-test 실습의 Data Flow Model은 위와 같습니다.
1. Data Load

Laod 함수를 통해 shop_ab_sales.csv 파일을 불러옵니다.

Delemiters를 Comma로 설정한 후,

pos_date(판매날짜), post_hour(판매시간), date_hour(판매일시)의 data type를 string으로 변경합니다.

Data가 모두 load되었네요!
A, B 대리점간 매출액 차이를 검정하기 전, 판매일시별 매출액을 확인하기 위해 Line Chart를 그려보겠습니다.

X-axis: date_hour(판매일시)
Y-axis: sales_amt(판매금액)
을 설정하고,
Color By option에 prom_yn(프로모션여부)와 shop_nm(대리점명)
을 지정하여 프로모션 여부에 따른 A, B 매출액 차이를 시각화하여 확인해보겠습니다!

연두색으로 표시된 부분이 대리점 A, 노란색으로 표시된 부분이 대리점 B인데요, 두 대리점간 매출액 차이가 있어보입니다. Line Chart로 파악한 차이가 통계적으로 유의한 차이인지, paired t-test를 통해 검정해보겠습니다.
2. A, B 대리점 매출액 데이터 결합
A 대리점과 B 대리점의 매출액을 비교하기 위해서는, A와 B 대리점의 매출액이 모두 존재하는 일시의 매출액을 비교해야 겠죠?
앞서 ↓아래 포스팅에서 다루었던 데이터 결합에 사용하는 innerjoin함수를 통해 두 지점의 매출액 데이터를 결합해보겠습니다.
https://yeenn-db.tistory.com/5
[삼성 SDS Brightics] 데이터 전처리 학습③ - 데이터 결합, 행/열 결합 및 데이터 형태 변환
안녕하세요! Brightics 서포터즈 2기 yeenn입니다. 지난 포스팅에서는 데이터 전처리 과정 중 데이터 정제에 관한 학습과정을 다루었는데요, 이번 포스팅에서는 효율적인 데이터 분석을 위해 꼭 필
yeenn-db.tistory.com
먼저, Filter 함수를 통해 A대리점과 B대리점의 데이터를 각각 추출해보겠습니다.


※ '_' 꼭 따옴표를 넣어주세요!
Select Column 항목에 대리점 변수 shop_nm을 불러와 'A' 대리점과 'B' 대리점을 추출하였습니다.

Join Type: Inner Join
Left Keys: date_hour
Right Keys: date_hour
를 지정하여 Run을 눌렀습니다.
공통된 데이터를 추출하다보니 396개의 Row가 391개의 Row로 줄어들었네요!
또, 이후 t검정을 수행할 때 편의를 위해 A 대리점의 데이터에 해당하는 left suffix에 _a와
B 대리점의 데이터에 해당하는 right suffix에 _b를 입력해줍니다.
3. 프로모션 여부별 Paired T-test
다음은, 프로모션 여부별 A, B 대리점의 매출액에 차이가 있는지 알아보기 위해 Paired T-test를 수행해보겠습니다.


First Column: sales_amt_a(A 대리점의 매출액)
Second Column: sales_amt_b(B 대리점의 매출액)
Alternatives: Two Sided
Group by: prom_yn_a
설정창에 위와 같이 지정한 다음 Run을 눌러주세요.
프로모션의 수행여부에 따른 매출액을 확인하는 것이 목적이기 때문에, Group By option에 prom_yn_a를 넣어줍니다.
※ Hypothesized Difference는 디폴트값인 0을 그대로 사용하는데요.
이와 같은 경우는 First Column과 Second Column을 반대로 하면, 검정통계량의 부호는 반대로 나오나 p-value는 동일합니다. 그러나, Hypothesized Difference가 0이 아닌 경우는 First Column과 Second Column가 반대로 입력되었을 때, 의도한 결과와 다른 결과가 산출될 수 있으므로 주의하도록 합니다!
자, 그럼 결과를 살펴볼까요?
Group by에 지정한 prom_yn 변수는 프로모션이 수행된 'Y'와 수행되지 않은 'N'인 경우로 나뉘어져 있는데요, 각각의 결과가 결과표에 출력되는 것을 확인할 수 있습니다.

먼저, 프로모션 기간이 아닌 경우,
검정통계량(t-value)는 약 1.612이고,
p-value가 0.108이므로 0.05보다 크기 때문에 유의수준에서 귀무가설 H0를 기각할 수 없습니다.

그러나 프로모션 기간인경우,
검정통계량(t-value)는 약 5.582이고,
p-value가 약 3.505e-07 = 3.505*(10^-07) < 0.05이므로,
0.05 유의수준에서 귀무가설 H0를 기각할 수 있습니다.
정리해보자면, 프로모션기간이 아닐 떄는 A, B대리점간 매출액 차이가 유의하지 않으나,
프로모션 기간에는 A, B 대리점 매출액 차이가 유의하다고 판단할 수 있습니다!
[독립표본 T검정 independent two sample t-test실습]
독립표본 t검정은 두 개의 그룹간 모집단 평균 차에 대한 검정방법인데요, paired t-test와는 다르게 각 그룹에 대한 짝을 짓지 않고 두 그룹간 평균차이에 대한 검정을 진행합니다.
그렇기 때문에 paired t-test의 경우, 짝을 지어야 하기 때문에 두 그룹의 관측치 개수가 같아야 하지만, 독립표본 t검정에서는 관측치의 개수가 꼭 같을 필요가 없습니다!
여기서, 평균차이에 대한 검정을 위해서 단순히 평균만을 가지고 검정을 하지는 않고, 분산을 사용하게되는데요,
두 표본간 평균차이가 크면 클수록 ↑,
그룹 내 분산이 작으면 작을수록 ↓,
검정통계량은 커집니다. ↑
독립표본의 검정통계량은 t-분포를 따르기 때문에, 검정통계량이 커질수록 p-value가 작아지고, 귀무가설을 기각하게 됩니다.
그럼, 동일한 dataset으로 독립표본 t검정또한 진행해보겠습니다!
앞서 정리한 paired t-test와의 차이점에 유의하면서 분석과정을 봐주시면 좋을 것 같아요.
1) 상황: A 대리점은 제품의 판매량을 늘리기 위해 일정기간 프로모션을 수행하였으나, B 대리점은 프로모션을 수행하지 않았다.
2) 실습 목표: A 대리점의 프로모션 수행시와 미수행시를 비교하여 매출액이 유의미하게 증가하였는지 파악한다.
→ 매출액이 유의미하게 차이가 나는지 검정하고자 Two sample T test를 수행한다.
3) 귀무가설 H0: 프로모션 여부별 A대리점의 매출액 차이는 없다.
0. Data Flow Model 구성

Independent Two sample T-test를 위한 data flow model구성은 위과 같습니다.
1. Data Load

위와 같은 dataset을 동일한 방법으로 load해주세요.
data flow모델을 새로 구성해도 되지만, 별도의 처리를 한 데이터이기 때문에 다시 변수상태를 설정하기 번거롭다면
Brightics의 함수 연결 기능을 활용하여
Data Flow Model에서 paired t-test의 load 함수에 이후 함수들을 추가하여 연결해주시면 됩니다!
2. A 대리점 data 추출

분석 대상이 A 대리점이므로,
Select column 항목에 대리점 데이터 shop_nm을,
조건에 'A'를 지정하여
A 대리점만 추출합니다.
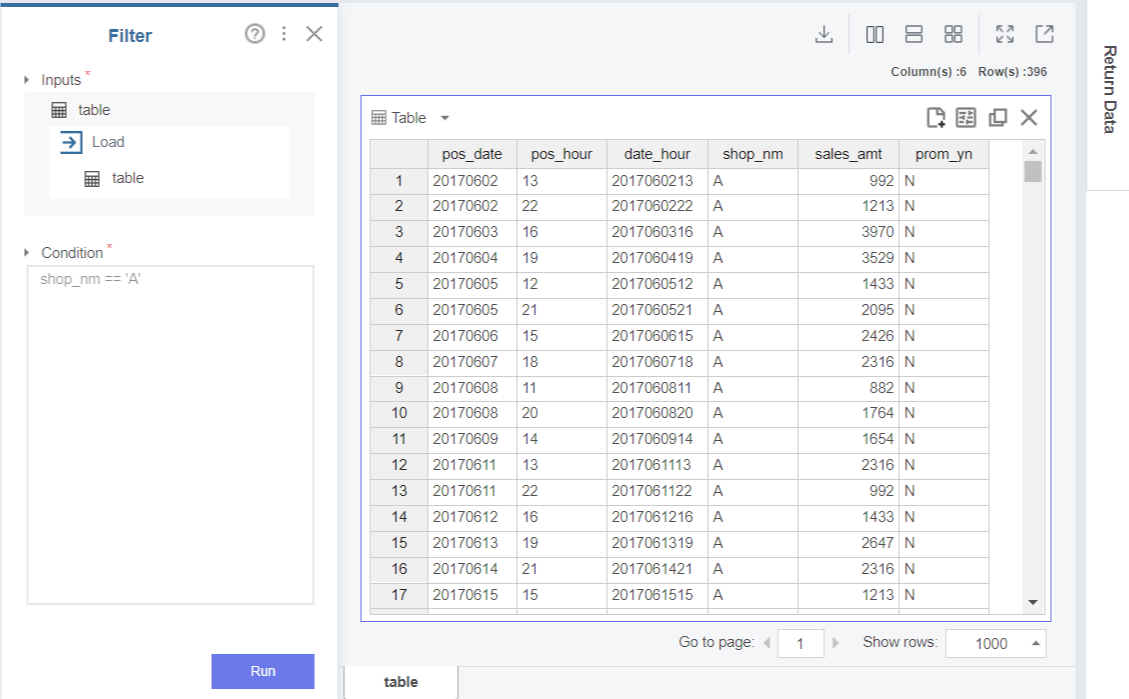
A 대리점 data만 추출되었네요!
3. 프로모션 여부별 매출액 차이 확인
1) Line Chart
다음은, 브라이틱스의 시각화 chart를 활용하여 프로모션 여부별 매출액 차이를 확인해보겠습니다.

시간에 따른 매출액의 변화를 살펴보기 위해, Line Chart를 선택하였습니다!
Chart Type: Line
X-axis: date_hour
Y-axis: sales_amt
위와 같이 지정한 후,
프로모션 여부별 매출액 차이를 살펴보기 위해 Color By 항목에 프로모션 여부 변수 prom_yn을 지정해줍니다.
Color by: prom_yn

파란색으로 표시된 부분이 프로모션이 수행된 기간의 매출액을 나타내는 지표입니다.
promotion_Y의 매출액이 미세하게 더 높아보이지만, 아직은 유의미한 차이를 보이는지 확언할 수는 없을 것 같습니다.
2) Box Plot

다음은, 프로모션별 매출액을 살펴보기 위해
Chart Type: Box plot
X-axis: prom_yn
Y-axis: sales_amt
를 지정한다음,
프로모션 여부별 매출액을 구분하기 위해
Separte Color을 ON으로 설정해줍니다!

Box Plot 구성은 위와 같습니다!
프로모션을 수행했을 때의 매출액이 조금 더 높아보이네요.
그럼, 이러한 매출액 차이가 프로모션 수행여부에 따라 통계적으로 유의미하게 차이가 나는지를 알아보기 위해 Two Sample T-test로 검정해보겠습니다.
3) Two Sample T-test

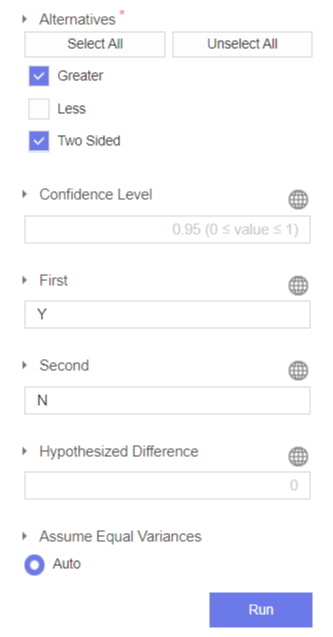
Response Column: 매출액 sales_amt,
Factor Column: 프로모션 여부 prom_yn
를 지정해줍니다.
Alternatives에는 프로모션 수행시(Y)가 미수행시(N)보다 매출액이 커지는지 검정하기 위해서 Greater을,
매출액이 차이가 나는지 검정하기 위해서 Two Sided를 지정하고,
First에는 prom_yn의 Y를,
Second에는 prom_yn의 N를 지정합니다.
Two Sample T-test와 등분산
독립표본의 t검정의 검정통계량은 두 표본에 대해 등분산인지 여부에 따라 분모의 수식이 달라진다는 특징을 갖는데요,
그래서 검정시 "두 그룹의 분산은 동일하다"라는 등분산성을 고려하여 등분산 검정 결과에 적합한 검정통계량을 사용하여야 합니다. Brightics에는 이러한 과정을 간편하게 수행하는 옵션을 제공합니다.
위 설정창의 Assume Equal Variances항목에는 Auto를 지정해주는데요,
이 항목은 등분산 검정결과에 맞는 검정통계량을 사용할 수 있게 해주는 옵션입니다!

출력 결과를 살펴볼까요?
검정 통계량 T-value는 약 2.030(반올림)이며,
단측 검정의 경우, p-value는 0.022로, 유의 수준 5%에서 귀무가설을 기각합니다.
양측 검정의 경우, p-value는 0.043으로 0.05보다 작아 유의수준 5%에서 귀무가설을 기각합니다.
따라서, A대리점의 매출액은 프로모션을 수행한 기간이 수행하지 않은 기간보다 유의미하게 높은 차이가 있다고 결론을 내릴 수 있습니다!
이것으로 T검정에 관한 포스팅을 마치도록 하겠습니다!
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.



