
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 삼성SDSBrightics
- kaggle
- 데이터분석
- 회귀모형평가
- SDSBrightics
- 삼성sds
- EDA
- BrighticsStudio
- 서울시상권분석
- ProDS
- 브라이틱스데이터분석
- 골목상권데이터분석
- Brightics
- Kaggle출전
- 브라이틱스
- houseprice
- Datascientist
- IT멘토링
- 분석모델링
- 모델링
- 브라이틱스서포터즈
- 코딩없이데이터분석
- 상권배후지
- associateDS
- Brightics서포터즈
- samsungsds
- 삼성자격증
- AdSP
- 데이터분석대외활동
- 데이터전처리
- Today
- Total
Database for Everything
[삼성 SDS Brightics] 의사결정나무(Decision Tree) 분류 모델 - 포도주의 품질을 분류해보자 본문

안녕하세요! yeenn입니다.
정말 오랜만에 작성하는 것 같은 개인 분석실습 포스팅...
이번 ProDS 시험을 준비하면서 듣던 강의의 마지막 차시였던 Decision Tree Model을 사용해 Brightics로 실습하는 과정을 담았습니다!
[이론 학습]
의사결정나무
의사결정나무(Decision Tree)는 의사결정규칙(decision rule)을 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류(classification)하거나 예측(prediction)을 수행하는 분석방법입니다. 분석과정이 나무구조에 의해서 표현되기 때문에 판별 분석(Discriminant Analysis), 회귀분석(Regression Analysis), 신경망(Neural Networks) 등과 같은 방법들에 비해 연구자가 분석과정을 쉽게 이해하고 설명할 수 있다는 장점을 가지고 있습니다.
출처: 통계청「통계분석연구」제4권 제1호(99.봄) 61-83 데이터마이닝 의사결정나무의 응용
또한, 의사결정나무는 분류(classification)와 회귀(regression) 모두 가능합니다. 범주나 연속형 수치 모두 예측할 수 있다는 말인데요, 이러한 의사결정나무의 범주예측, 즉 분류 과정은 다음과 같습니다.
-목표 변수 범주형: 분류 나무
-목표 변수 연속형: 회귀 나무
새로운 데이터가 특정 terminal node에 속한다는 정보를 확인한 뒤 해당 terminal node에서 가장 빈도가 높은 범주에 새로운 데이터를 분류하게 됩니다.

머신러닝 - 4. 결정 트리(Decision Tree)
결정 트리(Decision Tree, 의사결정트리, 의사결정나무라고도 함)는 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나입니다. 결정 트리는 스무고개 하듯이 예/아니오 질문을
bkshin.tistory.com
의사결정나무 Process



먼저 위와 같이 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나누고, 나뉜 각 범주에서 또 다시 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 데이터를 나눕니다. 이 때, decision tree에 분석자가 특정한 parameter을 추가하는 과정이 필요한데, 이를 거치지 않으면 과대적합(Overfitting)의 문제가 발생하여 예측력이 떨어지게 됩니다.
의사결정나무의 과대적합 방지법
1. 정지규칙(Stopping Rule)
정지규칙은 일정 크기 이상으로 나무가 자라지 못하게 하는 방법으로, 일반적으로
-노드의 모든 데이터가 하나의 클래스일때(불순도0%)
-트리의 깊이가 지정한 값에 도달할 때
-해당 노드에 포함된 데이터 수가 적을 때
-불순도의 감소량이 지정된 값보다 적을 때
위와 같은 경우에 적용합니다.
2. 가지치기(Pruning)
가지치기 기법은 나무에 가지가 너무 많다면 오버피팅(과대적합)이라 볼 수 있습니다. 여기서 가지치기란 나무의 가지를 치는 작업을 말합니다. 즉, 최대 깊이나 터미널 노드의 최대 개수, 혹은 한 노드가 분할하기 위한 최소 데이터 수를 제한하는 것입니다.
* 해당 실습은 Brightics Gitbub에 수록되어있는 데이터를 활용하였으며, 위 포스팅은 '브라이틱스와 함꼐하는 데이터 분석' 도서를 참고하여 작성되었습니다.
[실습]
Dataset 설명
| 변수명 | 설명 |
| fixed_acidity | 산도 관련 수치 |
| volatile_acidity | 산도 관련 수치 |
| critic_acid | 시트르산 수치 |
| residual_sugar | 당도 잔여 수치 |
| chlorides | 소금 함유량 |
| free_sulfur_dioxide | 이산화황 관련 수치 |
| total_sulfur_dioxide | 이산화황 관련 수치 |
| density | 수분 밀도 |
| pH | 산도 |
| sulphates | 황산염 |
| alcohol | 알코올 |
| quality | 춤질(Label) |
0. Work Flow Model

이번 실습의 work flow moel은 위와 같습니다!
1. Data Load
Local file에서 winequality_whit.txt와 winequality_red.txt을 불러와주세요.
동일한 방식으로 Load하면 됩니다!


Delimiter은 Semicolon으로 설정해주세요.



현재 모델에서는 두 dataset을 load해주었기 때문에
red wine 과 white wine으로 load한 데이터를 구분하는 것이 필요하다고 판단했습니다!
함수 블록을 클릭하면, 좌측에 해당 함수 블록의 이름과 path가 뜨는데요,
여기서 물음표 옆의 점 세개 버튼을 눌러주시면 Function을 Edit할 수 있는 창이 나옵니다!
이후 분석시 헷갈리지 않게
winequality_whit.txt는 Load: Wine으로,
winequality_red.txt는 Load: Red로
Function명을 변경해주었습니다.
2. 파생변수 추가
데이터의 종류는 red wine과 white wine 두 가지인데요, data정보를 확인해보면, 데이터의 형식과 내용이 같고 포도주의 종류만 다르기 때문에 이 데이터를 하나의 데이터로 결합해주기로 했습니다.
하지만 이러한 데이터의 경우 결합하기 전 데이터를 그대로 합치면 red wine 과 white wine의 구분이 없어지기 때문에, 두 와인을 구분해줄 수 있는 파생변수를 생성한 후 결합하도록 하겠습니다!


Add Function Column을 불러와 각 data에 is_red라는 redwine 여부라는 파생변수를 생성한 후,
레드와인인 경우, is_red에 1을,
화이트 와인인 경우, is_red에 0을 지정합니다!
3. 데이터 결합
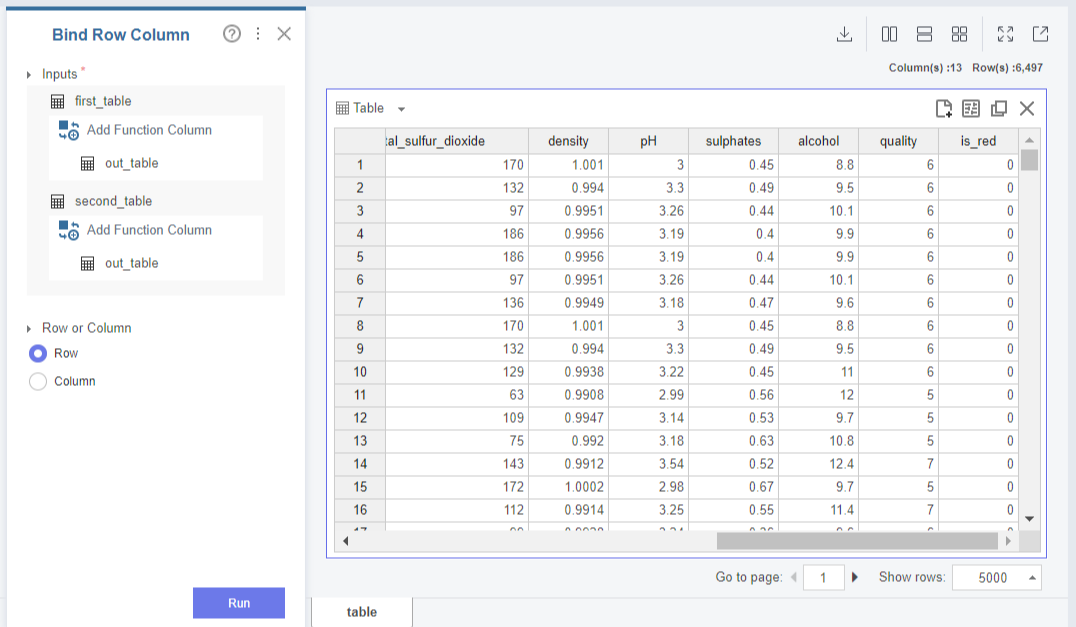
파생변수 is_red를 생성한 두 데이터를 Bind Row Column으로 결합합니다.
Row or Column은 Row로 지정해주세요!
4. 데이터 분할

다음은, Split Data함수를 통해 학습데이터(70%)와 테스트 데이터(30%)를 나누겠습니다.
default값으로 두면, 7:3으로 분리가 됩니다!
Seed값은 123으로 지정해주었습니다.
5. 의사결정나무 Classification 모델 Train
종속변수가 범주형 변수인 포도주의 등급이기 때문에,
의사결정나무 분류모델을 이용하여 의사결정나무를 학습시키겠습니다.
특성변수에는 종속변수인 Quality변수를 제외한 12개 변수를 넣고,
종속변수에는 Quality 변수를 지정해줍니다.
앞서 Split함수에서 지정한 Seed와 동일한 값인 123 역시 Seed에 지정해주세요.

Train을 통해 출력된 의사결정나무를 살펴보면, Depth가 default값 1로 두고 만들어진 모델이기 때문에, 과대적합의 문제가 발생하여 예측력이 굉장히 떨어지는 모델이라고 볼 수 있습니다.
따라서, 추가적으로 뿌리의 깊이와 노드 수를 파라미터를 통해 제한하여 예측력이 이전보다 상승한 의사결정나무를 만들어보겠습니다!

Feature Columns: Quality 제외 12개 특성변수
Label Column: Quality 변수
Criterion: Gini
Splitter: Best
Max Depth: 10
Max Leaf Nodes: 50
로 파라미터를 재설정하고, Run을 누르면, 위와 같은 의사결정나무가 출력된 것을 확인할 수 있습니다.

출력된 Decision Tree 아래에는 Quality 분류모델에서 중요하게 작용했던 feature importance가 출력됩니다!
특성 중요도를 살펴보면, alcohol, volatile_acidity 변수가 의사결정나무 생성에 상당히 중요한 역할을 하고 있는 것을 확인할 수 있었습니다.
6. 의사결정나무 Classification Test 예측
그 다음은, split함수로 분리한 test data에 대한 예측을 진행해보겠습니다.
Decision Tree Classification Prediction 함수를 볼러와,
Input table에 test_table을 설정한 후,
Suffix Type: Label 을 설정하고
Run을 눌러주세요.

결과 table을 확인해보면, prediction 변수가 생성된 것을 확인할 수 있습니다!
이제 이러한 prediction을 바탕으로 분류모델을 평가하는 과정을 진행해보겠습니다.
7. 분류모델 평가

Evaluate Classification 함수를 불러온 후, 아래와 같이 parameter을 설정해줍니다!
Lable Column에는 종속변수인 Quality를 넣고,
Prediction Column에는 예측값인 prediction을 설정하고 Run을 누르면,
우측과 같은 분류모델 결과 값이 출력됩니다.

분류 정확도는 약 0.5543으로 평가되었으며,
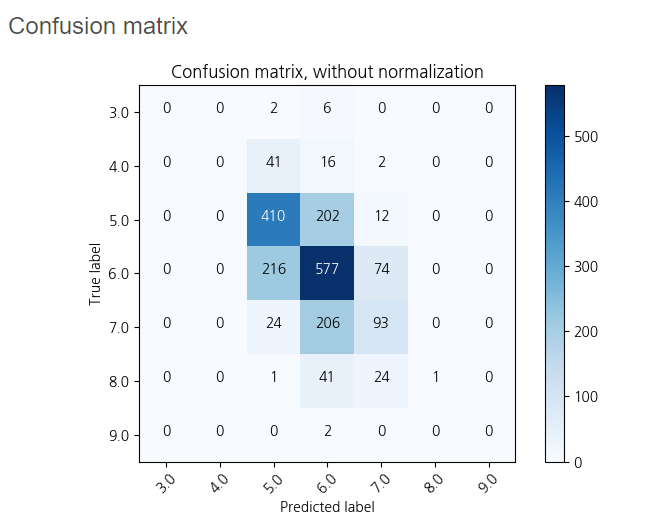

대체적으로 와인의 등급은 5-6등급으로 평가하고 있음을 확인할 수 있었습니다!
다음 포스팅은 아마 개인분석프로젝트 관련 포스팅이 될 것 같습니다!
다음 포스팅도 기대해주세요:)
본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.