
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- houseprice
- 브라이틱스서포터즈
- BrighticsStudio
- 브라이틱스
- Brightics서포터즈
- AdSP
- 데이터분석대외활동
- kaggle
- 회귀모형평가
- 삼성자격증
- SDSBrightics
- 삼성sds
- 서울시상권분석
- 골목상권데이터분석
- samsungsds
- 코딩없이데이터분석
- EDA
- 데이터전처리
- Datascientist
- Brightics
- associateDS
- 상권배후지
- 분석모델링
- 브라이틱스데이터분석
- 모델링
- 데이터분석
- Kaggle출전
- ProDS
- IT멘토링
- 삼성SDSBrightics
- Today
- Total
Database for Everything
[R 프로그램] 기초부터 다지기(1) - 데이터 전처리_조건에 맞는 데이터 추출하기 ( filter(), %>%, %in% ) 본문
데이터 전처리에 필요한 dplyr 패키지 내장 함수
| dplyr 함수 | 기능 |
| filter() | 행 추출 |
| select() | 열(변수) 추출 |
| arrange() | 정렬 |
| mutate() | 변수 추가 |
| summarise() | 통계치 산출 |
| group_by() | 집단별로 나누기 |
| left_join() | 데이터 합치기(열) |
| bind_rows() | 데이터 합치기(행) |
데이터 프레임으로 내장 데이터 출력하기
먼저, dplyr 패키지를 load한 후, csv_exam.csv 파일을 데이터 프레임으로 만들어 출력한다.
dplyr 패키지가 설치되지 않았다면, install.packages("dplyr")을 입력하여 해당 패키지를 설치한다.

출력 결과의 class 변수열을 보면, 데이터가 5개 반의 학생들로 구성되어 있다는 것을 알 수 있다.
Filter() 사용하여 데이터 추출하기
dplyr패키지의 filter()을 이용해 1반 학생들의 데이터만 추출하였다.

dplyr 패키지는 파이프 연산자 '%>%' 를 이용해 함수들을 나열하는 방식으로 코드를 작성한다.
이 때, 단축키 Ctrl + Shift + M 을 누르면 %>% 가 삽입된다.
(함수의 파라미터를 지정할 때에는 '='를, 같다를 의미할 때에는 '==' 와 같이 등호를 작성해야 한다)
이번에는 1반 학생들이 아닌 데이터를 추출해보았다.
변수가 특정 값이 아닌 경우에는 '!=' 기호를 사용한다.

Filter() 사용하여 데이터 추출하기 (조건문 포함)
filter함수를 통해 수학점수가 50점을 초과하는 데이터, 70점 이상인 데이터를 추출하였다.

Filter()에 특정변수와 부등호를 넣어 특정 조건에 해당하는 데이터만 추출할 수 있다.
여러 조건을 충족하는 행 추출하기
1반이면서 수학점수가 50점 이상인 경우의 데이터를 추출하였다.

and를 의미하는 기호 '&'를 사용해 조건을 나열하면 여러 조건을 동시에 충족하는 행을 추출할 수 있다.
여러 조건 중 하나 이상 충족하는 행 추출하기
수학 점수가 90점 이상이거나 영어 점수가 90점 이상인 경우의 데이터를 출력하였다.

또는 (or)을 의미하는 '|' 기호를 이용하면 여러 조건 중 하나라도 충족하는 데이터를 추출할 수 있다.
목록에 해당하는 행 추출하기
1, 3, 5반에 해당하는 경우의 데이터만 추출하였다.

변수의 값이 지정한 목록에 해당될 경우만 추출해야 할 상황에는 '|' 기호를 이용해 지정한 목록의 조건들을 위와 같이 나열하여 연결해주면 된다.
이 때, 매치 연산자 '%in%" 를 사용하면 코드를 조금 더 간편하게 작성할 수 있다.
앞선 경우와 동일하게 매치 연산자를 이용하여 1, 3, 5반의 데이터를 추출해보았다.
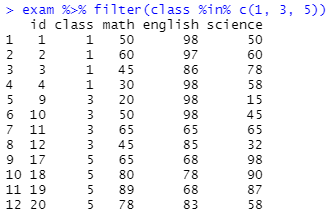
%in% 기호와 c()를 이용해 조건 목록을 입력하면 되는데, 이 때, c()안에 지정한 조건 목록을 입력해주면 된다.
추출한 행으로 데이터 만들기

R프로그램의 변수 할당 기호는 '<-' 이다. 새 변수를 생성할 때와 같이 <- 를 이용하여 필터링을 마친 새로운 데이터를 생성한 후, mean()을 이용하여 각 반의 수학점수 평균을 구해보았다.
※ 위 포스팅은 「Do it! 쉽게 배우는 R 데이터 분석(이지스리퍼블리싱)」 도서를 바탕으로 작성되었습니다.
'R' 카테고리의 다른 글
| [R 프로그램] 인터랙티브 그래프(2)_plotly 패키지로 인터랙티브 그래프 만들기 (0) | 2021.11.26 |
|---|---|
| [R 프로그램] 인터랙티브 그래프(1)_미국 주별 강력 범죄율 인터랙티브 지도 시각화 - ggiraphExtra 패키지 (0) | 2021.11.25 |
| [R 프로그램] 기초부터 다지기-데이터 전처리(2)_데이터 정렬, 요약, 통합하기 (0) | 2021.11.07 |
| [R 프로그램] 기초부터 다지기-파생변수 만들기(Derived Variable)_조건문 생성 (0) | 2021.09.09 |
| [R 프로그램] 기초부터 다지기 - 데이터 파악 함수 사용하기_head(), tail(), View(), dim(), str(), summary() (0) | 2021.09.08 |



