
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Kaggle출전
- BrighticsStudio
- 상권배후지
- 골목상권데이터분석
- IT멘토링
- houseprice
- Datascientist
- 코딩없이데이터분석
- 데이터분석대외활동
- 데이터전처리
- 분석모델링
- 삼성자격증
- samsungsds
- 데이터분석
- 브라이틱스데이터분석
- 삼성sds
- 모델링
- SDSBrightics
- 삼성SDSBrightics
- kaggle
- EDA
- 회귀모형평가
- associateDS
- 브라이틱스
- 서울시상권분석
- Brightics
- 브라이틱스서포터즈
- Brightics서포터즈
- AdSP
- ProDS
- Today
- Total
Database for Everything
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 상권 데이터분석_Hierarchical Clustering (계층적 군집화) 본문
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 상권 데이터분석_Hierarchical Clustering (계층적 군집화)
Yeenn 2021. 10. 19. 00:28
안녕하세요!
Brightics 서포터즈 yeenn입니다ㅎㅎ
드디어...마지막 모델링 시간이 돌아왔어요..!!!!
안올 것 같았는데 벌써 마무리할 시간이 다 되었다니..마음이 싱숭생숭합니다ㅠㅠ

소감은 조금 더 뒤에 이야기하는 것으로 하고..
각설하고 본문으로 바로 들어가보겠습니다!
지난 포스팅에서는 회귀분석까지 진행했었는데요,
↓
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_다중회귀분석, QGIS Geo
안녕하세요! Brightics 서포터즈 yeenn입니다. 매 주 Brightics와 함께하는 분석과정과 블로그 포스팅이 이제는 정말 일상이 된 것 같아요!! 새삼 느끼는 거지만... 거의 미션 20주차 가까이 접어들다 보
yeenn-db.tistory.com
이번 마지막 모델링 시간에는
계층적군집화(Hierarchical Clustering) 분석을 진행해보도록 하겠습니다!
Hierarchical Clustering(계층적 군집분석)
군집분석의 종류
군집분석은 크게 계층적 군집화와 분할적 군집화로 나뉩니다!
군집분석의 형태를 그림으로 나타내면 아래와 같은 이미지로 표현할 수 있습니다.

계층적 군집화 (hierarchical clustering) 란?
각 관측지를 하나의 최초 군집으로 지정한 후, 한번에 두개씩 하나의 군집으로 만들어, 모든 군집들이 하나의 군집이 될 때까지 군집들을 결합해 나가는 클러스터링 알고리즘이며, K Means와는 다르게 군집의 수를 미리 정해주지 않아도 됩니다.

* 와드연결법(Ward linkage) : 군집 평균과 군집 내 유클리디언 최소 증가 방식 *
와드연결법(Ward linkage)은 군집간의 거리에 따라 데이터들을 연결하기 보다는
군집내 편차들의 제곱합(within group sum of squares)에 근거를 두고 군집들을 병합시키는 방법인데요,
와드연결법은 군집분석의 각 단계에서 데이터들을 하나의 군집으로 묶음으로써 생기는 정보의 손실을
군집의 평균과 데이터들 사이의 오차제곱합(SSE)으로 아래와 같이 측정합니다.

먼저 각각의 데이터들은 그 자체가 각각 하나의 군집을 형성하고, 모든 i에 대해
SSE.i =0 이므로 SSE=0 이 됩니다.
이때, 군집을 만들어 가는 각 단계마다 군집의 모든 가능한 쌍들의 병합이 고려되는데, 각 단계에서
두 군집의 병합으로 인한 SSE의 증가분 (정보의 손실) 이 최소가 되도록 군집들을 병합시켜 새로운
군집을 만들게 되며,
이러한 와드연결법은 비슷한 크기의 군집끼리 병합하는 경향이 있습니다.
출처: https://m.blog.naver.com/wjddudwo209/220046493579
그럼, 계층적 군집화를 쉽게 예를 들어서 설명해볼까요?
1번째 군집화
“진돗개,세퍼드,요크셔테리어,푸들, 물소, 젖소" 로 계층적 군집 분석을 실행하면,
첫번째는 중형견, 소형견, 소와 같은 3개의 군집으로 묶일 수 있습니다.

2번째 군집화
이를 한번 더 군집화 하게 되면,
[진돗개,셰퍼드] 와 [요크셔테리어,푸들] 군집은 하나의 군집(개)로 묶일 수 있습니다!

3번째 군집화
마지막으로 한번 더 군집화를 하게 되면 전체가 한군집(동물)으로 묶이게 됩니다.

이렇게 단계별로 계층을 따라가면서 군집을 하는 것을 계층적 군집 분석이라고 하는데요,
계층적 군집 분석은 Dendrogram이라는 그래프를 이용하면 손쉽게 시각화 할 수 있습니다!

출처: https://bcho.tistory.com/1204 [조대협의 블로그]
이론을 살펴봤으니 그럼 본격적인 분석에 들어가보겠습니다...!
서울시(2015)는 골목상권 내 영세 소상공인이 주로 종사하는 업종을 외식업(10개), 서비스업(22개), 도소매업(11개)에 해당하는 생활밀착형 43개 업종으로 분류했는데요,
이러한 분류 기준에 따라 총 63개의 업종을
외식업/서비스업/도,소매업으로 업종 대분류하는 파생변수 "서비스_업종_대분류" 를 생성했었습니다!

이 변수를 어떻게 활용하면 좋을까, 생각하다가
각 업종 대분류별로 filtering한 후,
세부 업종별로 군집화시켜서 어떤 업종들이 대분류 내에서 같은 군집으로 묶이는지를 살펴보기로 했습니다.
같은 군집으로 묶이는 업종을 확인할 수 있다면
상권의 위치 선정이나, 업종별 제휴 영업 등의 운영방안 등을 위한 insight를 도출 할 수 있을 것 같아
계층적 군집화를 진행해보았습니다!
서비스_업종_대분류 변수 Filter
먼저, Filter 함수를 사용하여 도소매업/외식업/서비스업 으로
데이터를 필터링 해주었습니다.
[상권 / 상권배후지]




그 다음, 군집분석 이전 정규화를 위해

회귀분석 이전 PCA를 위해 사용했던 Normalization 함수 블럭과
업종별 필터링 함수블록을 연결시켜주었습니다.
* 계층적 군집화의 결과 창은 Brightics studio에서 아래와 같이 보여지게 되는데요,
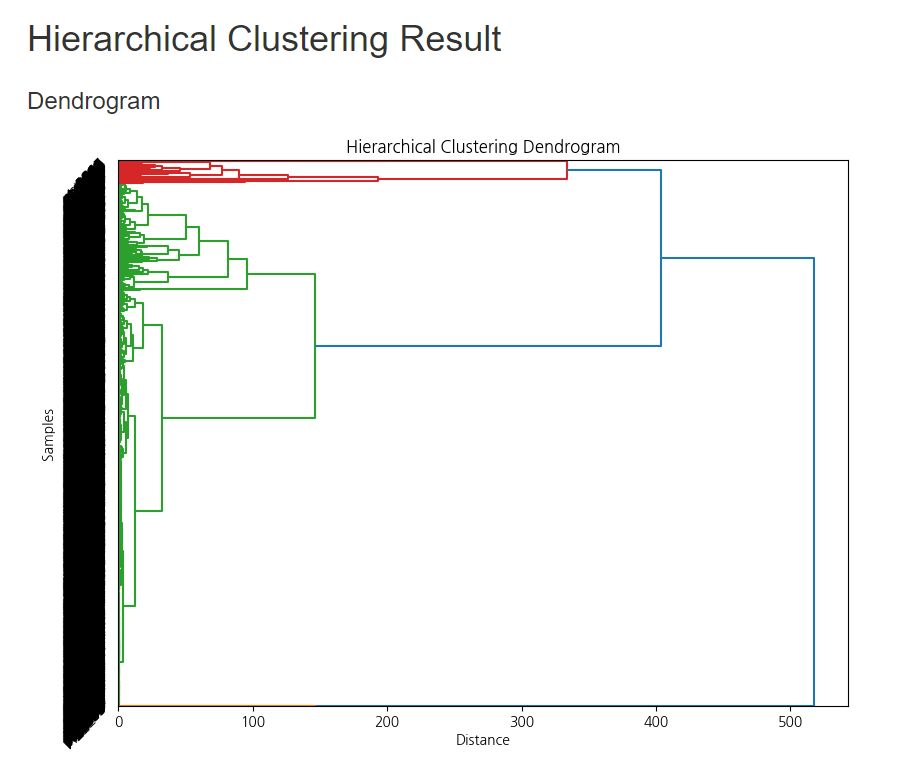
덴드로그램을 살펴보면
3개로 나누어질 때 군집간 거리가 가장 큰 것을 알 수 있는데요, (파란색 선)
이를 통해 'Maximum number of Clusters'(최대 군집 수) = 3 를 결정한 후, 군집을 나눌 수 있습니다!
* 아래의 모든 군집화 분석은 Linkage Method는 위의 이론 설명에서 언급한 와드연결법을 사용하여 진행되었습니다.
Hierarchical Clustering Post Process
[상권-도소매업]

상권-도소매업의 경우, Hierarchical Clustering의 Dendrogram 결과에 따라 최대 cluster 개수를 3개로 지정하였고, 이에 따라 Hierarchical Clustering Post Process를 이용하여 군집 분석을 진행하였습니다.
이후 군집분석의 결과를
100% Stacked Column 차트를 통해 확인해보았습니다!

Parameter:
x axis: cluster
y axis: 서비스 업종 코드명
color by: 서비스 업종 코드명
차트를 그려보니, 2번 군집> 3번 군집 >> 1번 군집 순으로 업종이 밀집해있는 것을 확인할 수 있었는데요,
업종 수가 많아 String summary 함수를 이용하여 세부 업종들을 확인해보았습니다.


String Summary
Input Columns: 서비스_업종_코드_명
Group by: Cluster
위와 같은 파라미터를 지정한 후,
군집별 대표적인 업종들을 살펴보니,
-군집1: 컴퓨터 및 주변장치 판매(컴퓨터 판매 수리)
-군집2: 전자상거래업, 조명, 문구, 일반의류, 슈퍼마켓 등
-군집3: 화장품, 편의점, 의약품, 슈퍼마켓, 청과상, 반찬가게 등
으로 분류됨을 확인할 수 있었습니다.
슈퍼마켓과 편의점 등 중복되는 업종을 제외하면,
군집2는 대체적으로 전자상거래와 의류관련 업종이,
군집3은 대체적으로 음식 관련한 업종이 다수 분포하고 있었습니다.
[상권-외식업]

상권-외식업 역시, Hierarchical Clustering의 Dendrogram 결과에 따라 최대 cluster 개수를 2개로 지정하였고, 이에 따라 Hierarchical Clustering Post Process를 이용하여 군집 분석을 진행하였습니다.

군집별 대표 업종들을 살펴보니,
-군집1: 패스트푸드, 치킨전문점, 중식, 분식 등
-군집2: 일식, 커피-음료, 분식 등
으로 분류됨을 확인할 수 있었습니다.
군집1에는 주로 배달업에 해당하는 업종들이 상대적으로 많이 분포하고 있네요!
[상권-서비스업]

상권-서비스업 역시, Hierarchical Clustering의 Dendrogram 결과에 따라 최대 cluster 개수를 3개로 지정하였고, 이에 따라 Hierarchical Clustering Post Process를 이용하여 군집 분석을 진행하였습니다.

군집별 대표 업종들을 살펴보니,
-군집1: 일반의원
-군집2: 미용실, 네일숍, 피부관리실, 노래방, 한의원, 치과의원 등
-군집3: 일반의원, 치과의원, PC방, 일반교습학원, 스포츠 강습 등
으로 분류됨을 확인할 수 있었습니다.
어릴 때 학원 다닌 경험을 생각해보면, 열에 여덟은 꼭 건물 지하에 PC방이 있었던 것 같은데ㅋㅋ
이렇게 실제로 군집화를 통해 확인해보니 신기했습니다..!
[상권배후지 - 도소매업]

상권배후지-도소매업 역시, Hierarchical Clustering의 Dendrogram 결과에 따라 최대 cluster 개수를 3개로 지정하였고, 이에 따라 Hierarchical Clustering Post Process를 이용하여 군집 분석을 진행하였습니다.

군집별 대표 업종들을 살펴보니,
-군집1: 미곡판매
-군집2: 일반의류, 안경, 철물점, 화초 등
-군집3: 편의점, 의약품, 슈퍼마켓, 육류판매 등
으로 분류됨을 확인할 수 있었습니다.
[상권배후지-외식업]

상권 배후지-외식업의 경우도 Dendrogram의 결과에 따라 cluster 개수를 2개로 지정했습니다.

군집별 대표 업종들을 살펴보니,
-군집1: 패스트푸드점, 중식음식점, 분식점, 치킨 전문점 등
-군집2: 일식, 커피-음료, 제과점 등
으로 분류됨을 확인할 수 있었습니다.
외식업의 경우, 도소매업과는 다르게 상권과 상권배후지가 비슷한 군집의 양상 을 보이고 있는 것을 확인할 수 있었습니다!
[상권배후지-서비스업]

상권 배후지-서비스업의 경우도 Dendrogram의 결과에 따라 cluster 개수를 2개로 지정하였습니다.

군집별 대표 업종들을 살펴보니,
-군집1: 자동차수리, 치과의원, 한의원, 노래방, 당구장 등
-군집2: 일반의원, PC방 등
으로 분류됨을 확인할 수 있었습니다.
+ 번외: Geocoding 도전
부제: 포기할 수 없다!
지난 포스팅에서 QGIS Program을 통해 서울시 상권의 geo코딩을 진행했었는데요,
Brightics에서의 지도 시각화를 포기할 수 없어...
(사실 모델링에 꼭 필요한 과정은 아니었지만! 시도해보고싶었습니다)
투영좌표계 → 경위도 좌표계
변환 방법을 멘토님께 문의메일을 드려 여쭈어봤었습니다.
(연휴가 끝나고 메일을 확인하시자마자 바로 답변을 주셨어요..! 이 자리를 빌려 다시금 감사드립니다 멘토님..♥)
Ds멘토님과 저희 조의 서포터 멘토님께 답변을 받은 결과,
1. 서울 열린데이터 광장에 경위도 좌표계 데이터셋을 구할 수 있는지 문의
2. 파이썬 코드로 좌표계 변환 수행
3. 꼭 Brightics로 모든 분석과정을 수행하지 않아도 괜찮다. QGIS 프로그램도 활용 가능
와 같은 해결방안을 정리해볼 수 있었습니다..!
위대로 먼저,
1. 서울 열린데이터 광장에 문의
원자료를 구한 서울 열린데이터 광장에 경위도 좌표계를 구할 수 있는지 문의해봤지만,

위와 같이 불가하다는 답변을 받았습니다...ㅎ
2. brightics.cs 문의
또 감사하게도 제 문의메일을 확인하신 멘토님이 brightics.cs에 대신 문의해주셔서

좌표계를 변환하는 파이썬 코드를 얻게되었습니다! (ESPG:5151 → ESPG:4326)
*참고한 포스팅
https://m.blog.naver.com/wideeyed/221243506770
[Python] 좌표변환 예제
UTM-K좌표계에서 WGS84좌표계로 변환하거나 WGS84좌표계에서 UTM-K좌표계로 변환해주는 예제...
blog.naver.com
이를 참고하여 아래와 같은 코드가 작성되었는데요,
library(pyproj)
import pandas as pd
import numpy as np
from pyproj import Proj, transform
#Projection 정의
proj_5181 = Proj(init='epsg:5181')
proj_4326 = Proj(init='epsg:4326')
#ESPG:5181을 ESPG:4326으로 변환한 Series데이터 반환
def transform_5181_to_4326(df):
return pd.Series(transform(proj_5181, proj_4326, df['XCNTS_VALU'], df['YDNTS_VALU']), index=['XCNTS_VALU', 'YDNTS_VALU'])
df = inputs[0]
df[['longitude', 'latitude']] = df_xy.apply(transform_5181_to_4326, axis=1)
df
상권 지리의 속성정보를 csv파일로 변환한 데이터를 불러와,
python script에서 위 코드를 실행했습니다.
그렇지만 돌아가지 않았다는...
error가 발생한 이유를 살펴보니,
코드 자체는 문제가 없어보이지만,
pyproj 라이브러리가 불러와지지 않아서 문제가 생긴거였더라고요..
그래서 jupyter notebook에서 따로 코드를 실행 해보기로 했습니다..ㅎㅎ
(정말 마지막 도전,,)
최종 결과는 다음주 최종 결과물 보고 레포트에!!
이렇게 해서, 마지막 모델링 과정까지 마무리하게 되었는데요!

최종 work flow 화면은 위와 같습니다!
상권과 상권배후지 data를 동시에 분석하느라 매우 대칭적인(?) work flow가 형성되었네요ㅋㅋ
이 모든 분석과정을 모두 코드를 작성하며 진행했다면
더욱 복잡하고 긴 코드가 완성되었을 것 같은데,
Brightics studio에서는 필요한 함수 블록을 열심히 drag&drop하고, copy&paste하며 모든 분석과정을 수월하게 수행할 수 있었습니다!!
타 분석툴과 비교될 수 없는 압도적인 Brightics의 장점이라고 생각합니다bbb
찐(?) 후기와 소감은 다음주 포스팅에서 더욱 길게 작성해보는 걸로 하고!
이번 포스팅은 여기까지 마무리해보도록 하겠습니다^-^!
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.



