
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 삼성sds
- Brightics
- 브라이틱스데이터분석
- 분석모델링
- 브라이틱스
- SDSBrightics
- samsungsds
- Brightics서포터즈
- kaggle
- 모델링
- 삼성SDSBrightics
- 상권배후지
- EDA
- BrighticsStudio
- houseprice
- 코딩없이데이터분석
- 삼성자격증
- IT멘토링
- Kaggle출전
- ProDS
- 데이터분석대외활동
- 서울시상권분석
- associateDS
- 데이터분석
- 골목상권데이터분석
- 데이터전처리
- 브라이틱스서포터즈
- AdSP
- Datascientist
- 회귀모형평가
- Today
- Total
Database for Everything
[R 프로그램] 한국복지패널데이터 분석 프로젝트(1) - 성별과 월급의 관계, 나이와 월급의 관계 파악하기 본문
https://github.com/youngwoos/Doit_R/blob/master/Data/Koweps_hpc10_2015_beta1.sav.md
GitHub - youngwoos/Doit_R: <Do it! 쉽게 배우는 R 데이터 분석> 저장소
<Do it! 쉽게 배우는 R 데이터 분석> 저장소. Contribute to youngwoos/Doit_R development by creating an account on GitHub.
github.com
실습데이터(Koweps_hpc10_2015_beta1.sav)는 위 링크에서 다운로드할 수 있다.
데이터 설명 및 Load
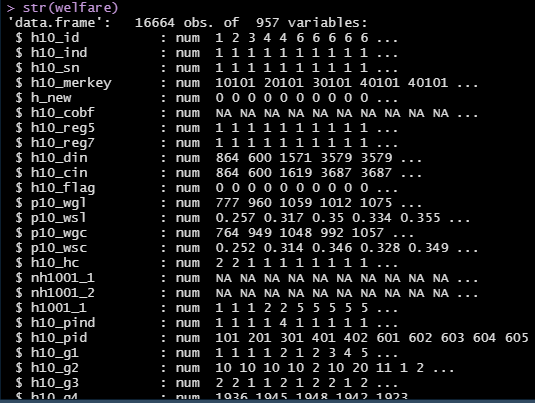
2016년에 발간된 복지패널데이터로, 6,914 가구, 16,664명에 대한 정보를 담고 있다.
SPSS를 다뤄본 사람이면 익숙할 데이터셋이다.
이 복지패널 데이터는 SPSS 전용 파일 .sav 로 되어있기 때문에, foreign패키지를 이용해 불러와야 한다. foreign패키지를 이용하면 SPSS, SAS, STATA등 다양한 통계분석 소프트웨어의 파일을 불러올 수 있다.

dplyr와 ggplot2 패키지는 이후 데이터 전처리와 시각화에 사용하기 위해 미리 load하였다.
데이터 살펴보기
View창을 통해서 살펴본 데이터.

str()을 통해 살펴본 데이터
summary()를 통해 살펴본 데이터

살펴본 결과, 매우 대규모의 데이터이기 때문에 데이터의 구조와 변수를 한 눈에 파악하기 어려웠으므로, 이해가 쉬운 이름으로 변수명을 변경한 다음, 변수를 차례차례 파악하는 것이 좋을 것 같다는 판단이 들었다.

변수명 변경
분석에 사용할 7개 변수의 이름을 아래와 같이 직관적으로 이해할 수 있도록 변경하였다.
sex=h10_g3, #성별
birth=h10_g4, #태어난 연도
marriage=h10_g10, #혼인 상태
religion=h10_g11, #종교
income=p1002_8aq1, #월급
code_job=h10_eco9, #직업 코드
code_region=h10_reg7 #지역 코드

● 성별에 따른 월급 차이
우선 sex(성별)변수의 type을 파악하기 위해 class()를 적용해본 결과, numeric 타입임을 알 수 있었고, table()로 각 범주에 몇 명이 있는지 알아본 결과 1에는 7578명, 2에는 9098명이 있는 것을 확인할 수 있었다. (1이면 남자, 2이면 여자) 또, 이를 통해 이상치는 없다는 것을 확인할 수 있었다.

sex변수의 값이 숫자 1과 2로 되어있어 보다 직관적인 문자로 바꾸기 위해 ifelse를 사용해 male과 female로 변경해주었다.

이후, qplot()을 통해 바꾼 출력결과를 시각화하였다.

_________
이제 월급항목을 살펴보았다. 월급변수(income)은 성별변수와 다르게 연속형변수이기 때문에 summary()로 요약통계량을 확인해야 한다.


qplot을 통해 살펴본 결과, x축이 2500까지 설정되어 있어 가장 데이터가 가장 많이 분포해있는 0-1000사이의 값이 잘 표현되지 않는 것을 확인할 수 있었다. 이를 해결하기 위해, xlim()을 이용해 0-1000까지만 표현될 수 있도록 축 설정을 추가해주었다.


축 설정을 통해 월급의 분포 상태를 조금 더 자세히 살펴볼 수 있었다. 0-250만원 사이에 가장 맣은 사람이 분포하고, 그 뒤로는 점차 빈도가 감소한다는 것을 알 수 있었다.
월급은 1-999사이의 값을 지니며, 모름/무응답은 9999로 코딩되어있다.
요약통계량을 살펴보면, 최솟값이 0, 최댓값이 2400, 결측치가 12030개 있는 것을 알 수 있다.
우선 이상치인 0값과 9999값을 결측처리한 후, table로 결측치를 확인해보았다.


두 변수의 전처리 작업을 마무리 한 후, 변수간 관계를 분석해보았다. 결측치를 필터링 한 후, 성별별 income을 살펴보았다.

남자는 312만원, 여자는 163만원으로 평균적으로 여성보다 남성의 울급이 약 150만원 더 많다는 것을 알 수 있었다.

geom_col()을 이용해 컬럼별 그래프를 살펴보았다. 역시 남성의 평균 월급이 여성의 월급보다 더 높은 것으로 나타남을 확인할 수 있었다.
● 나이에 따른 월급 차이
income변수는 앞서 살펴보았고, 나이변수를 살펴보기 위해 class(), summary(), qplot()을 샤용했다.


태어난 연도는 1900-2014사이의 값을 지니고, 모름/무응답은 9999로 코딩이 되어있다.
결측치가 있는지 확인해보니, False로 출력되어 결측치가 존재하지 않음을 알 수 있었다.

한국복지패널데이터에는 나이 변수가 없다. 2015년에 시행된 조사를 바탕으로 만들어진 데이터이므로, 2015-태어난연도 +1 로 나이 파생변수를 생성하였다.
파생변수 생성 후, summary(), qplot()을 통해 변수를 다시 살펴보았다.


나이에 따른 평균월급표를 만든 후, geom_line()을 통해 나이에 따른 월급변화를 살펴보았다.


출력된 그래프를 보면, 20대 초반에 100만원가량의 월급을 받고, 이후 평균 월급이 지속적으로 증가하다가, 50대 무렵 300만원 초반대로 가장 많은 월급을 받고, 그 이후로 지속적으로 감소하다가 70세 이후에는 20대보다 낮은 월급을 받는 것을 확인할 수 있다.
'R' 카테고리의 다른 글
| [R 프로그램] 한국복지패널데이터 분석 프로젝트(3) - 종교 유무에 따른 이혼율, 지역별 연령대 비율 (0) | 2021.12.04 |
|---|---|
| [R 프로그램] 한국복지패널데이터 분석 프로젝트(2) - 연령대별 월급차이, 직업별 월급 차이 파악하기 (0) | 2021.12.04 |
| [R 프로그램] 3D 물체 구현 - rgl 패키지 (0) | 2021.12.02 |
| [R 프로그램] 웹 크롤링 - 교보문고 주간 베스트 셀러 도서목록 불러오기 (0) | 2021.12.02 |
| [R 프로그램] 인터랙티브 그래프(3) - 대한민국 시도별 인구, 결핵 환자 수 단계 구분도 만들기 _ devtools, kormaps, ggi (0) | 2021.11.27 |



