
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- kaggle
- 삼성sds
- 모델링
- Brightics서포터즈
- 데이터분석대외활동
- Datascientist
- BrighticsStudio
- 상권배후지
- Brightics
- 삼성자격증
- 분석모델링
- ProDS
- 브라이틱스서포터즈
- AdSP
- 브라이틱스
- IT멘토링
- 코딩없이데이터분석
- samsungsds
- SDSBrightics
- 서울시상권분석
- 회귀모형평가
- 골목상권데이터분석
- Kaggle출전
- associateDS
- EDA
- 데이터분석
- 데이터전처리
- houseprice
- 삼성SDSBrightics
- 브라이틱스데이터분석
- Today
- Total
Database for Everything
[R 프로그램] 신용카드 고객 데이터 군집분석(1) 본문
분석 시나리오: 신용카드 고객데이터로 K-Means 군집분석을 수행하여 고객 Segementation에 활용하려고 한다.
해당 데이터는 아래 파일을 다운받아 사용하면 된다.
Data Load 및 필요 라이브러리 호출
read.csv로 german_credit_data.csv 파일을 불러온 후, 필요한 라이브러리를 호출하였다.
#데이터 load
bank<-read.csv("german_credit_data.csv")
#필요라이브러리
library(ggplot2)
library(lattice)
library(scales)
library(factoextra)
library(ggpubr)
library(dplyr)
library(data.table)Data 확인 및 Pre-Processing
head()와 str()로 데이터를 확인한 후, 필요없는 X컬럼을 삭제하고, 결측치를 확인한 후 삭제해주었다.
#데이터 확인
head(bank)
X Age Sex Job Housing Saving.accounts Checking.account Credit.amount Duration Purpose
1 0 67 male 2 own <NA> little 1169 6 radio/TV
2 1 22 female 2 own little moderate 5951 48 radio/TV
3 2 49 male 1 own little <NA> 2096 12 education
4 3 45 male 2 free little little 7882 42 furniture/equipment
5 4 53 male 2 free little little 4870 24 car
6 5 35 male 1 free <NA> <NA> 9055 36 education
str(bank)
'data.frame': 1000 obs. of 10 variables:
$ X : int 0 1 2 3 4 5 6 7 8 9 ...
$ Age : int 67 22 49 45 53 35 53 35 61 28 ...
$ Sex : chr "male" "female" "male" "male" ...
$ Job : int 2 2 1 2 2 1 2 3 1 3 ...
$ Housing : chr "own" "own" "own" "free" ...
$ Saving.accounts : chr NA "little" "little" "little" ...
$ Checking.account: chr "little" "moderate" NA "little" ...
$ Credit.amount : int 1169 5951 2096 7882 4870 9055 2835 6948 3059 5234 ...
$ Duration : int 6 48 12 42 24 36 24 36 12 30 ...
$ Purpose : chr "radio/TV" "radio/TV" "education" "furniture/equipment" ...
#데이터 전처리
is.na(bank)
sum(is.na(bank))
[1] 577
#X컬럼 제거
bank1<-bank[-1]
bank2<-na.omit(bank1)
문자형 변수인 Sex, Housing, Saving.accounts, Checking.account, Purpose의 더미변수를 생성하였다. str()을 통해 범주형 변수로 인코딩이 잘 되었는지 확인해보았다.
- Sex: male=1, female=2;
- Housing: own=1, free=2, rent=3;
- Savings.accounts: little=1, moderate=2, quite rich=3, rich=4;
- Checking.account: little=1, moderate=2, rich=3;
- Purpose: business=1, car=2, domestic appliences=3, education=4, furniture/equipment=5, radio/TV=6, repairs=7, vacation/others=8
#Sex, Housing, Saving,accounts, Chekcing.account, Purpose 더미변수 생성
bank3<-bank2
bank3[,2]<-ifelse(bank2[,2]=="male", 1, ifelse(bank2[,2]=="female",2,3))
bank3[,4]<-ifelse(bank2[,4]=="own", 1, ifelse(bank2[,4]=="free", 2, ifelse(bank2[,4]=="rent", 3,4)))
bank3[,5]<-ifelse(bank2[,5]=="little", 1, ifelse(bank2[,5]=="moderate", 2, ifelse(bank2[,5]=="quite rich", 3, ifelse(bank2[,5]=="rich", 4, 5))))
bank3[,6] <- ifelse(bank2[,6] == "little", 1, ifelse(bank2[,6] == "moderate", 2, ifelse(bank2[,6] == "rich", 3, 4)))
bank3[,9] <- ifelse(bank2[,9] == "business", 1, ifelse(bank2[,9] == "car", 2, ifelse(bank2[,9] == "domestic appliances", 3, ifelse(bank2[,9] == "education", 4, ifelse(bank2[,9] == "furniture/equipment", 5, ifelse(bank2[,9] == "radio/TV", 6, ifelse(bank2[,9] == "repairs", 7, ifelse(bank2[,9] == "vacation/others", 8, 9))))))))
str(bank3)
'data.frame': 522 obs. of 9 variables:
$ Age : int 22 45 53 35 28 25 24 22 60 28 ...
$ Sex : num 2 1 1 1 1 2 2 2 1 2 ...
$ Job : int 2 2 2 3 3 2 2 2 1 2 ...
$ Housing : num 1 2 2 3 1 3 3 1 1 3 ...
$ Saving.accounts : num 1 1 1 1 1 1 1 1 1 1 ...
$ Checking.account: num 2 1 1 2 2 2 1 2 1 1 ...
$ Credit.amount : int 5951 7882 4870 6948 5234 1295 4308 1567 1199 1403 ...
$ Duration : int 48 42 24 36 30 12 48 12 24 15 ...
$ Purpose : num 6 5 2 2 2 2 1 6 2 2 ...
- attr(*, "na.action")= 'omit' Named int [1:478] 1 3 6 7 9 17 18 20 21 25 ...
..- attr(*, "names")= chr [1:478] "1" "3" "6" "7" ...
중복값을 확인하고, 처리해주었다.
#중복값 확인
which(duplicated(bank3))
integer(0)
sapply(bank3, function(x) length(unique(x)))
Age Sex Job Housing Saving.accounts Checking.account Credit.amount Duration
52 2 4 3 4 3 503 30
Purpose
8Credit.amount, Duration과 다른 변수간 상관관계 확인
lattice 라이브러리를 사용하면, xyplot을 통해 변수간 상관관계를 한 눈에 파악할 수 있다.
Credit.amount, Duration변수와 Sex, Job, Housing, Saving.accounts, Checking.account변수간 상관관계를 시각화하여 살펴보았다.
#Credit.amount와 다른변수간의 상관관계
xyplot(Sex ~ Credit.amount, bank3)
xyplot(Job ~ Credit.amount, bank3)
xyplot(Housing ~ Credit.amount, bank3)
xyplot(Saving.accounts ~ Credit.amount, bank3)
xyplot(Checking.account ~ Credit.amount, bank3,
grid = TRUE)
#Duration와 다른변수간의 상관관계
xyplot(Sex ~ Duration, bank3)
xyplot(Job ~ Duration, bank3)
xyplot(Housing ~ Duration, bank3)
xyplot(Saving.accounts ~ Duration, bank3)
xyplot(Checking.account ~ Duration, bank3,
grid = TRUE)




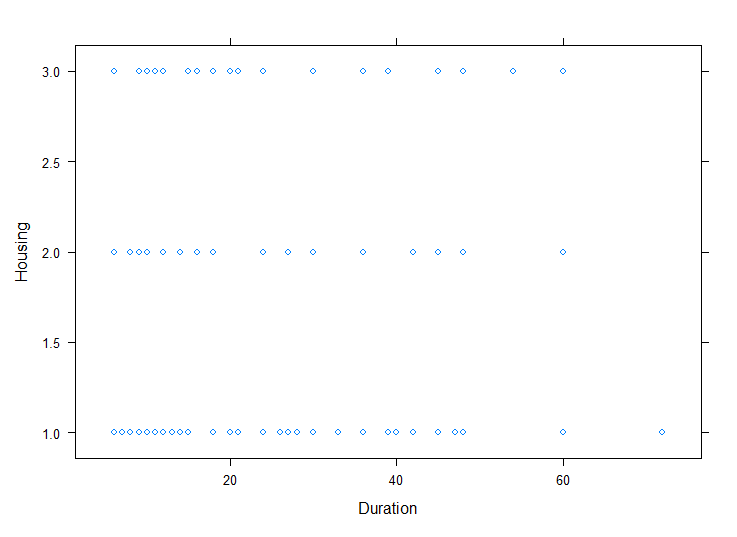


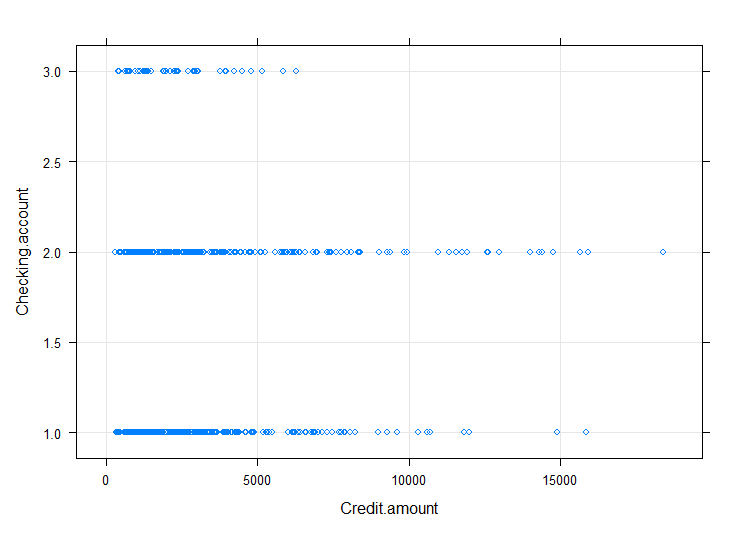
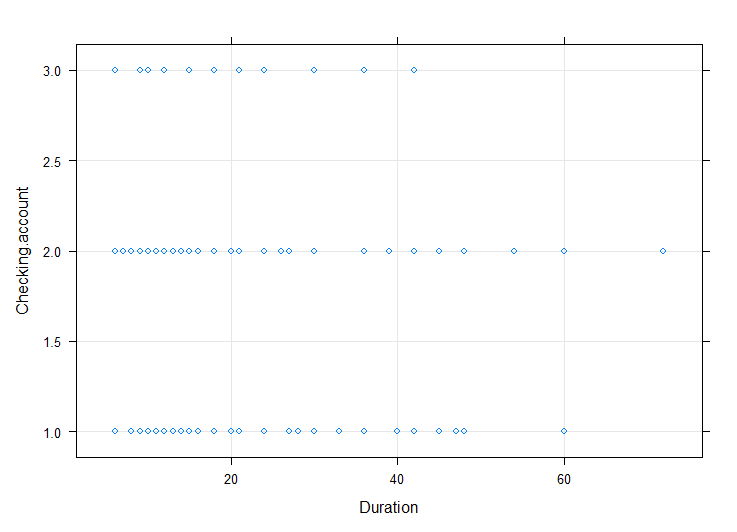
상관관계 분석 결과,
1. 남성이 여성보다 더 많은 credit amount를 가지며, credit 듀레이션이 더 길었다.
2. Jobs "3"과 "2"가 jobs "1"과 "0"에 비해 더 많은 credit amount를 가지고 있다.
3. 집을 가지고 있는 사람은 credit을 더 많이 가지고 있었고, credit 듀레이션은 더 길었다.
4. 부유한 사람들은 credit을 거의 요구하지 않았지만, 가난한 사람들은 더 많은 credit을 요구하였다.
5. 적정한 저축을 하는 사람들이 그렇지 않은 사람들에 비해 듀레이션이 길었다.
*Duration: 이자율과 만기에 따라 원금 회수시 걸리는 평균 기간
추가 변수 EDA
직업별 만기의 평균을 Credit amount별로 비교하는 그래프를 그려보았다.
#직업별 Credit amount 비교
mid<-mean(bank3$Duration)
ggplot(bank3, aes(x=Job, y=mid, colour=Credit.amount))+
theme(axis.text.x=element_text(angle=90, vjust=0.2))+
geom_bar(stat="identity")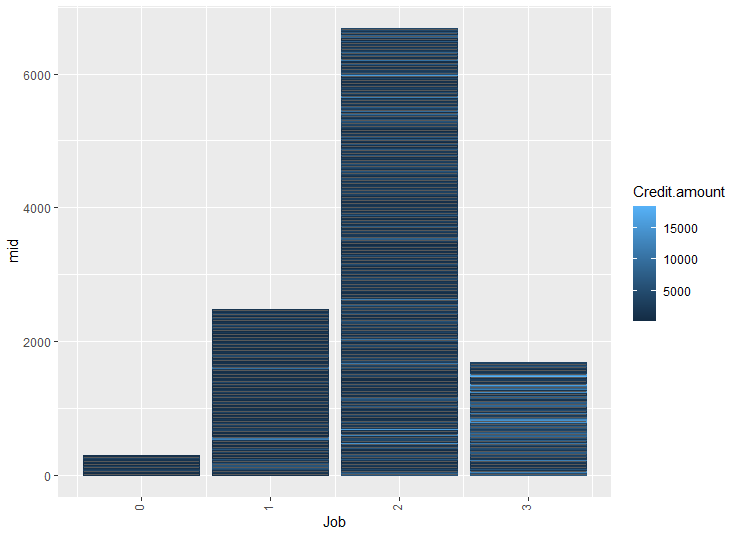
Credit 축적의 목적을 Housing변수별로 비교하는 그래프를 그려보았다.
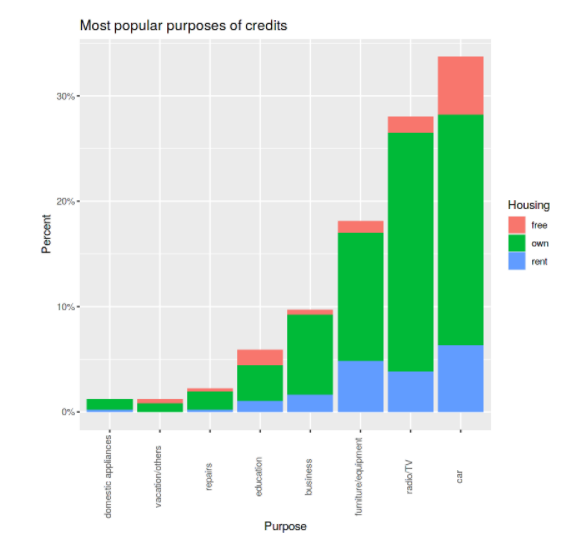
다음 포스팅에서는 K-means 군집분석을 수행해볼 예정이다.
'R' 카테고리의 다른 글
| [R 프로그램] Cookie Cats 게임 데이터_A/B Test(1) (0) | 2022.03.29 |
|---|---|
| [R 프로그램] 신용카드 고객 데이터 군집분석(2) (0) | 2022.01.21 |
| [R 프로그램] 나이브베이즈알고리즘으로 mushroom 분류하기 (0) | 2021.12.16 |
| [R 프로그램] R markdown으로 데이터 분석 보고서 만들기 (0) | 2021.12.09 |
| [R 프로그램] 의사결정나무 - 사과의 품질 분류하기 (0) | 2021.12.09 |



