[삼성 SDS Brightics] Brightics 서포터즈와 함께 코딩없이 Kaggle Competition 도전하기!_데이터 전처리, EDA, 회귀모형 적합②

https://www.youtube.com/watch?v=GjWg866IvYE
시작하기 전 홍보..!ㅎㅎㅎ
드디어 저희 3조 Brightic3의 영상이 유튜브에 업로드 완료되었습니다!
사실 업로드는 n일전에 되었지만..블로그 홍보는 처음이네요!!

학교 단톡방에 뿌리고...커뮤니티에 뿌리고...동창 단톡방에 뿌리고..친척 단톡방에 뿌리고...동아리 단톡방에 뿌리고..어머니 친구모임 단톡방(?)에도 뿌리고..
사실 처음에 조회수가 잘 나오지 않아서,, 애가 탄 나머지 팀원들끼리 의기투합해서ㅋㅋㅋ
사람들이 많이 볼 수 있는 곳이라면 물불 가리지 않고 유튭 링크를 공유했는데 효과가 좀 있었으려나요!!ㅎㅎㅎ 정말 우리 팀원들 모두 고생해서 만든 영상이니 이 포스팅을 보시는 분들은 한 번씩 확인해주시면 감사하겠습니다! (좋아요와 댓글도 부탁드려요..다들 보기만 하고 지나가는 것 같아,,)
앞으로 위 영상은 포스팅때마다 공유하도록 하겠습니다(뿌듯)


빠질 수 없는 Brightic3 회의 인증샷vv
놀랍게도 대면한적은 1-2번 밖에 없지만..(코로나ㅠ) 7월부터 지금까지 매주 2-3번씩은 만나서 너무도 친근해져 버린 우리 3조..
우리 가족만큼 많이 보는 것 같네요
기나긴 회의 끝에 House price data의 EDA와 전처리 과정 정리가 마무리 되었습니다!이번 포스팅은 이를 바탕으로 Brightics를 활용하여 EDA와 데이터 전처리를 진행하는 과정을 담아보도록 하겠습니다:)


House price data의 변수가 굉장히 많고, 수치형 변수과 범주형 변수, 범주형 변수 내에서도 구분지어야 하는 명목형 변수과 순서형 변수가 존재했기 때문에 저희 3조는 위와같이 구글독스에서 데이터를 하나하나 살펴보며 전처리 방식을 정리했습니다. (힘들었어요....ㅎ)
2주차의 데이터 전처리는 이를 바탕으로 이루어졌기 때문에 조금 더 자세하고 과정이 복잡하니 잘 따라와주세요!
해당 포스팅은 지난 포스팅 ↓ 과 내용이 이어집니다!
https://yeenn-db.tistory.com/24
[삼성 SDS Brightics] Brightics 서포터즈와 함께 코딩없이 Kaggle Competition 도전하기!_데이터 전처리①
안녕하세요, Brightics 서포터즈 yeenn입니다! 드디어! Brightic3의 팀분석 프로젝트가 시작되었습니다. Brightic3의 팀분석프로젝트 주제는 "Kaggle의 Houseprice 데이터를 활용한 집값예측+Kaggle Competition..
yeenn-db.tistory.com
Add Function Column으로 파생변수 생성

YearBuilt: Original construction date
YearRemodAdd: Remodel date (same as construction date if no remodeling or additions)
변수 중에는 건물이 지어진 날짜와 건물이 리모델링 된 날짜를 확인할 수 있는 변수(YearBuilt, YearRemodAdd)가 있었는데요, 이 두 변수로 파생변수 하나를 생성했습니다!
YearRemodAdd변수는 리모델링이 진행되지 않은 경우 건물이 지어진 날짜와 동일한 변수값을 갖는데요, YearRemodAdd-YearBuilt변수를 새로 생성하게 되면 리모델링을 진행한 시기의 값은 0을 초과하는 값, 리모델링을 진행하지 않은 시기의 값은 0값으로 구분을 지을 수 있게됩니다.
이 파생변수를 통해 리모델링여부와 리모델링 시기를 모두 한 번에 파악할 수 있다고 판단하였기 때문에 위와 같이 Add Function Column을 통해 YearRemodAdd-YearBuilt 의 값을 갖는 new column 'NewYearRemod'을 생성해주었습니다!
수치형 변수들의 상관관계 확인
Brightics에는 변수의 정보, 상관관계, 시각화된 그래프 등을 한 눈에 확인할 수 있는 Profile Table 함수가 있는데요, 이를 통해 반응변수 SalePrice와의 상관관계가 높은(0.5이상인) 수치형 변수를 몇 개 추려내어 확인해보도록 하겠습니다.
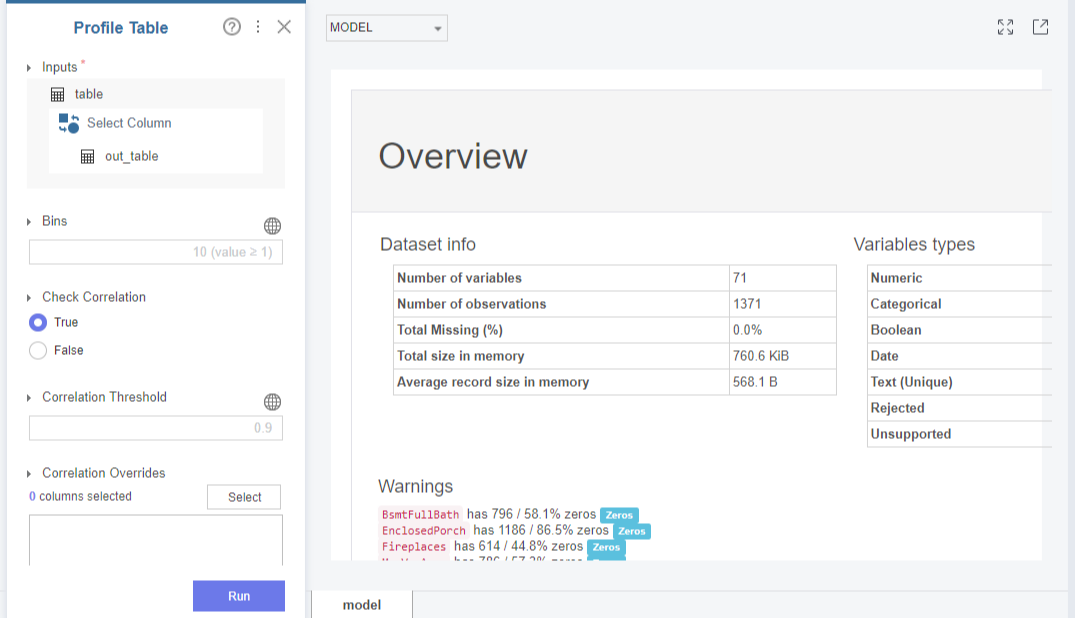
Profile Table을 불러와
Check Correlation항목에 True를 누르고, 나머지는 default값 그대로 파라미터를 설정하여 Run을 눌러주면
위와 같은 dataset information의 overview를 확인할 수 있습니다!
지금 제가 파악하고자 하는 것은 변수간 상관관계를 나타내는 Heatmap이기 때문에, 우측 상단의 확장 버튼을 이용해 더 큰 화면에서 visualization 결과를 살펴보도록 하겠습니다.

Profile Table함수를 사용하면, 위와 같은 상관관계 Heatmap를 확인할 수 있습니다!
이전에 개인분석실습을 진행할 때 profile table함수를 사용한 적이 있었는데, 그 때는 결측치와 skewness를 파악하는 용도로만 썼어서 이런 기능이 있는 줄 몰랐다지요...
Correlation함수로 열심히 낑낑(?) 대다가 brightics의 이런 유용한 함수 기능을 또 다시 알게되어서 뿌듯합니다bb
빨간 색은 양의 상관관계 정도를, 파란 색은 음의 상관관계 정도를 나타내는 색인데요, 이를 활용해 x축 우측에 위치한 SalePrice와의 높은 양의 상관관계를 나타내는 붉은색 변수들을 추려내 보도록 하겠습니다.
진한 빨간색을 나타내는 변수들은 다음과 같습니다.
OverallQual
TotalBsmtSF
_1stFlrSF
GrLivArea
FullBath
TotRmsAbvGrd
Garagecars
GarageArea
YearBuilt
그 다음은 위 변수들을 Correlation함수에 넣어 정확한 상관관계정도를 파악해보도록하겠습니다!

Correlation함수를 불러와
Input Columns에 위의 9개 변수와 SalePrice변수를 넣은 후,
Method: Pearson을 설정하여 Run을 눌러주면
아래와 같은 상관관계 결과표가 나오게 됩니다!


이를 통해 위 변수들이 아래와 같은 0.5이상의 높은 상관관계를 보이고 있는 것을 확인할 수 있었습니다!
OverallQual - 0.79
TotalBsmtSF - 0.60
_1stFllrSF - 0.60
GrLivArea - 0.71
FullBath - 0.56
TotRmsAbvGrd - 0.54
GarageCars - 0.64
GarageArea - 0.61
YearBuilt - 0.51
이 중 SalePrice변수와 가장 높은 상관관계를 보이는 OverallQual, GrlivArea변수와 SalePrice의 관계를 box plot과 Scatter plot을 통해 시각화해보도록 하겠습니다.
● OverallQual - SalePrice
(X-axis: OverallQual / Y-axis: SalePrice)

OverallQual 변수는 housprice data의 수치형 변수 중 SalePrice와 상관 계수가 0.79로 가장 큰 변수이며, 집의 전반적인 재료와 마감의 평가를 나타내는 세부 수치는 1부터 10까지 존재하고 있습니다.
또, SalePrice와 Overall Quality는 양의 상관 관계를 보이며, 전반적으로 상향 곡선의 형태를 보이고 있는 것을 확인할 수 있습니다.
특별히 튀는 이상치는 없어보이네요!
● GrLivArea - SalePrice
(X-axis: GrLivArea / Y-axis: SalePrice / Lines: Trend Line(Show)

GrLivArea변수는 수치형 변수 중 SalePrice와 상관 계수가 0.71로 두 번째로 큰 변수이며, 우상향하는 모습을 보이는 scatter plot을 통해 대체적으로 집의 면적이 높을 수록 높은 가격을 보이고 있는 것을 확인할 수 있었습니다.
Scatter Plot 파라미터 설정창을 보면 Line을 표시할 수 있는 파라미터가 존재하는데, 이 때 이 Line 항목 중 Trend Line을 선택하고 show를 누르면, 위와 같이 산점도의 추세선 또한 같이 확인할 수 있습니다!
One Hot Encoder을 사용한 명목형 변수의 더미변수화
LotConfig: Lot configuration
Inside Inside lot
Corner Corner lot
CulDSac Cul-de-sac
FR2 Frontage on 2 sides of property
FR3 Frontage on 3 sides of property
LandSlope: Slope of property
Gtl Gentle slope
Mod Moderate Slope
Sev Severe Slope
HousePrice data의 변수를 살펴보면, 위와 같은 범주형변수 중 순서가 존재하지 않는 '명목형 변수'들을 확인할 수 있는데요, 이러한 변수를 0과 1로 쉽게 인코딩해주기 위해 one hot encoder함수를 사용했습니다!

데이터 전처리 회의 때 정리했던 해당 명목형 변수들을 Input Columns에 넣고 Run을 누르면 위와같이 인코딩이 완료가 됩니다.
Prefix와 Suffix Type은 변수명을 어떻게 설정하느냐에 따라 설정이 달라질텐데, 저는 디폴트 값 그대로 사용해주었습니다!
Add Function Columns를 사용한 범주형/수치형변수의 인코딩
위처럼 명목형 변수는 one hot encoder함수로 처리는 했는데...
전처리 회의를 하면서 데이터 처리방식에 대해 논했던 변수들 중, 특정 값에만 치우쳐 있는 변수들의 경우는 어떻게 처리할지 고민하다가,
0값을 기준으로 존재여부를 판단하거나, 실행여부를 판단할 수 있도록 0값과 1값으로 변수를 인코딩하기로 결정했습니다!
ex. Fence 변수(Fence유무로 분리(0값/1값))
Fence: Fence quality
GdPrv Good Privacy
MnPrv Minimum Privacy
GdWo Good Wood
MnWw Minimum Wood/Wire
NA No Fence
이러한 경우, One Hot Encoder를 쓸 수 없는 상황이기 때문에 동일한 처리가 필요한 위와 같은 변수들을 Add Function Columns 함수를 사용하여 여러개의 파생변수를 동시에 생성하기로 하였습니다.


Add Function Column함수를 불러와 흰색 바탕의 Add Column창을 클릭하면, 좌측과 같은 함수 입력창이 나타나는데요, 왼쪽에는 새로운 변수명을 입력하고, 우측에는 생성하고자 하는 변수의 설명을 입력해주었습니다.
금방 나누고자 하는 0값과 1값으로 분리가 된 것을 확인할 수 있네요!!
Brightics덕분에 함수 블록을 4개로 늘릴 뻔한 상황을 한 개의 블록으로 줄일 수 있었습니다 쵝오bb
Filter함수를 통한 불필요값 제거
Brightics에는 특정한 내용을 필터링할 수 있는 Filter함수가 있는데요,
이를 이용해 값이 거의 없는 것과 마찬가지였던 범주형 변수 BsmtFinType1의 Na 값(지난 전처리 때 None값으로 변환함)을 필터링해주도록 하겠습니다.
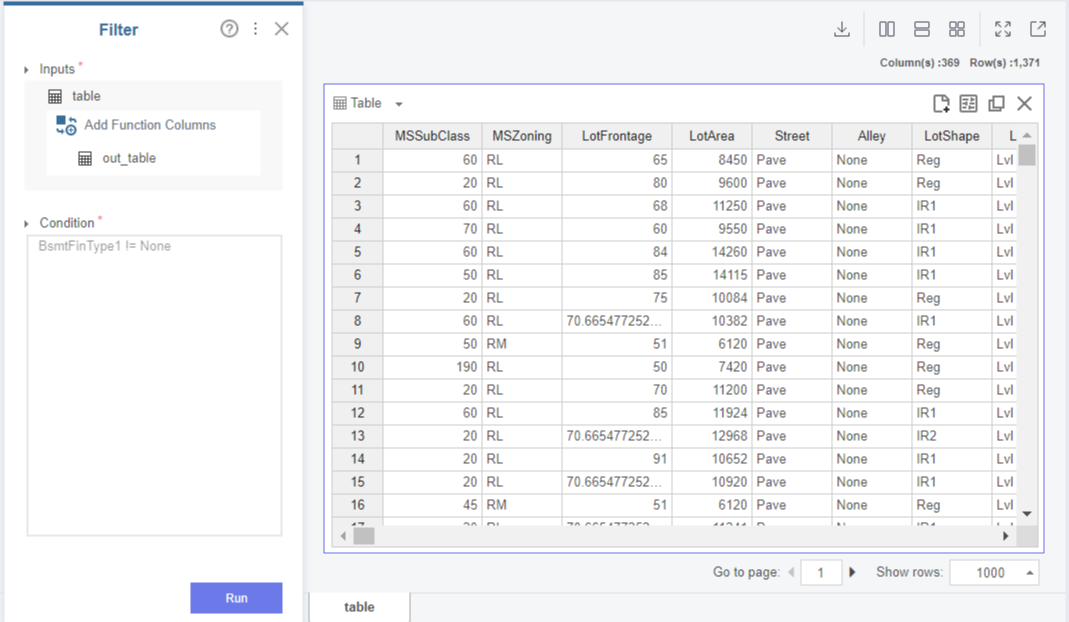
변수를 설정하고, =, !=와 같은 Condition을 입력하고, 필터링을 걸 값을 입력해주면 filtering이 완료됩니다!
Add Column을 사용한 순서형 변수의 인코딩
앞서 범주형 변수 중 순서가 없는 명목형 변수의 경우 One Hot Encoder로 인코딩을 했었는데요,
그렇다면 순서가 있는 순서형 변수의 경우는 어떻게 인코딩을 할까요?
Brightics에서는 Label Encoder함수가 존재하는데요, 0과 1로 이루어진 다수의 열을 만드는 One Hot Encoder와 달리 Label encoder는 하나의 열에 서로 다른 숫자를 입력해줍니다.
범주형 데이터를 수치형 데이터로 반환할 때 주로 이 Label Encoder을 사용하기 때문에 이번 House price data의 순서형 변수에도 Label Encoder을 적용하려 했으나, 한 가지 문제점이 있었습니다.
Label Encoder은 알파벳 순서대로 숫자를 부여하는데요, 아래와 같이 변수의 명확한 순서관계가 존재하는 경우,
ex. BsmtQual: Evaluates the height of the basement (지하실의 높이 Quality 판단)
Ex Excellent (100+ inches)
Gd Good (90-99 inches)
TA Typical (80-89 inches)
Fa Fair (70-79 inches)
Po Poor (<70 inches
NA No Basement
Label Encoder을 쓰면 이러한 대소관계를 제대로 반영하지 못하게 되고, 이는 예측력을 크게 떨어뜨릴 수 있는 요인이 될 수 있다고 판단했습니다.
하늘이 무너져도 솟아날 구멍은 있다(?)!
그래서! Add Column함수를 통해 수치형으로 변환이 필요한 순서형 변수들의 값들을 순서를 포함한 수치로 입력해주었습니다.
ex) 'Ex'==5 / 'Gd'==4 / 'TA'==3 / 'Fa'==2 / 'Po'==1 / Else 0

아래와 같이 Add Column 함수 블록을 drag&drop으로 쉽게 이어붙여 나머지 순서형 변수의 값도 반환해주었습니다!

반응변수 SalePrice의 Log 변환
지난 포스팅에서 Statistic Summary로 반응변수 SalePrice의 Skewness를 확인했었는데요!

right skewed된 Saleprice의 비대칭성 문제를 해결하기 위해
Add Function Column을 통해 SalePrice의 로그 변환또한 실행해주었습니다.

Linear Regression-학습데이터로 모형 적합
그 다음, house price의 train data로 회귀모형을 적합하기 위해 Linear Regression Train을 활용해보겠습니다!

R-Squared 값과 Adj. R-squared값을 보니 1과 가까운 0.970이상의 값을 보이고 있어 설명력이 좋은 모형이라고 판단할 수 있었습니다!
그 다음, 예측변수의 회귀계수에 대한 p-value가 0.05보다 작기 때문에 회귀계수가 유의하다고 판단되었고, 이를 통해 예측변수와 반응변수 new_SalePrice간의 유의한 선형관계가 존재함을 확인할 수 있었습니다.
지금까지 Train Data의 전처리과정과 Linear Regression을 활용한 모형적합과정까지 살펴보았는데요,
다음 포스팅에서는 이러한 전처리 과정을 test data에 적용한 후,
stacking등의 방법을 활용하여 가장 예측력을 높일 수 있는 회귀모델을 찾아보도록 하겠습니다!
본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.