[삼성 SDS Brightics] 데이터 전처리 학습① - 데이터 정제(data cleansing) 이론 및 실습

안녕하세요!
드디어 브라이틱스 서포터즈의 2번째 미션이 시작되었습니다.
이번 개인 미션은 공개 dataset을 이용하여 Brightics Studio를 활용한 실습을 본격적으로 진행해보는 것인데요,
앞으로 약 3주의 시간동안 Brightics studio를 통해
데이터 전처리과정과 통계분석과정을 살펴보도록 하겠습니다!
오늘 진행할 데이터 전처리 학습은 데이터 정제(data cleansing)입니다.
데이터 정제(Data Cleansing)란?
"데이터 정제는 원천 데이터 혹은 통합된 원천 데이터의 포맷을 통일하거나, 누락값을 제거하거나, 구분자 (delimiter) 를 입력하거나, 데이터의 불필요한 값을 제거하는 등의 작업을 통해 고품질 데이터의 요건을 갖추는 작업을 의미합니다."
출처: http://www.softline.biz/2018/sub02_02.html
데이터를 분석하는 과정에서, 우리는 고품질의 데이터를 얻기 위해 데이터에 대한 면밀한 조사를 거쳐
결측값과 이상값을 처리하게 됩니다.
[이론학습]
1. 결측값 처리
현실세계의 많은 데이터들은 기록 누락, 미응답, 수집 오류 등 많은 사유들로 인해 결측값이 포함되어 있습니다. 이러한 결측값들을 효율적으로 처리하기 위해서는, 정보의 손실을 최소화하고, 분석결과에 편향이 발생하지 않도록 면밀한 조사를 통해 결측값을 처리하는 방법을 이용해야 합니다.
| 결측값 처리
1) 완전 제거법(list-wise-deletion)
-결측치가 포함되어 있는 데이터를 제거하고 모든 변수에 대한 값이 관측된 경우의 데이터만을 이용하는 방법
2) 평균 대체법(mean-value imputation)
-데이터 내의 결측값을 관측된 데이터의 평균을 이용하여 대체하는 방법
3) 핫덱 대체(hot-deck imputation)
-동일한 조사에서 다른 관측값으로부터 얻은 자료를 이용해 결측치를 대체하는 방법
4) 다중대체법(multiple imputation)
-평균대체법이나 핫덱대체법과 같은 단순 대체법을 1회만 하지 않고 n번 반복하여 결측치를 대체한 완전한 데이터 n개
를 만들어 분석하는 방법
2. 이상값 처리
이상값(이상치)은 데이터의 분포상 다른 데이터들과 동떨어진 것을 일컫습니다. 이상값은 데이터 수집과정상의 오류로 인해 발생할 수 있으나, 이상값 자체가 데이터의 cluster을 구분할 수 있는 중요한 정보를 내포할 수도 있기 때문에 이러한 이상값들을 면밀히 조사하여 탐지한 후 처리하는 과정이 필요합니다.
| 이상값 탐지
1) 상자그림(box plot)
Tukey가 1977년에 제안한 방법으로, 상자 그림의 바깥 경계를 정의하고 경계를 벗어나는 경우를 이상값으로 판단하 는 방식. 일반적으로 경계값 1.5를 기준으로 이상값을 판단함.
2) 히스토그램
데이터의 분포를 확인하는 방법 중 하나로, 히스토그램을 통해 대부분의 데이터 분포로부터 멀리 떨어진 이상값 후보 의 빈도수와 값의 크기도 확인 가능
3) 산점도
두 수치형 변수의 관계를 파악할 때 사용되는 대표적인 차트로서, 이상값 탐지에서는 두 변수간 관계에서 동떨어진 값이 무엇인지 탐색 가능
4) 거리기반 탐지기법
-유클리드 거리(Euclidean distance)
-마할라노비스 거리(Mahalanobis distance)
-극단적 스튜던트화 이탈(ESD)
| 이상값 처리
1) 이상값 제외
-이상값으로 탐지된 데이터를 제외하는 기법으로, 이상값이 포함된 관측값의 다른 변수값도 같이 제외되므로 정보손
실과 추정량 왜곡이 발생 가능
2) 이상값 대체 - 윈저화(winsorization)
-이상값으로 탐지된 관측값을 원래의 값보다 작게 하거나 크게 하는 기법
3) 변수 변환
-log, sqrt 변환등으로 이상값이 포함된 변수를 변환하면 값의 단위를 줄이면서 이상값의 크기를 감소시킬 수 있음
참고: 브라이틱스와 함께하는 데이터분석(책)
[실습]
위에서 설명한 이론학습이 충분히 선행되었다면,
다음은, 이를 바탕으로 데이터에서 결측값과 이상값을 처리해보는 실습을 진행해보겠습니다!
※ 데이터는 Brightics github에 수록되어 있는 실습데이터 outlier_missing.txt를 이용하였습니다.
1. Data Flow Model 구성
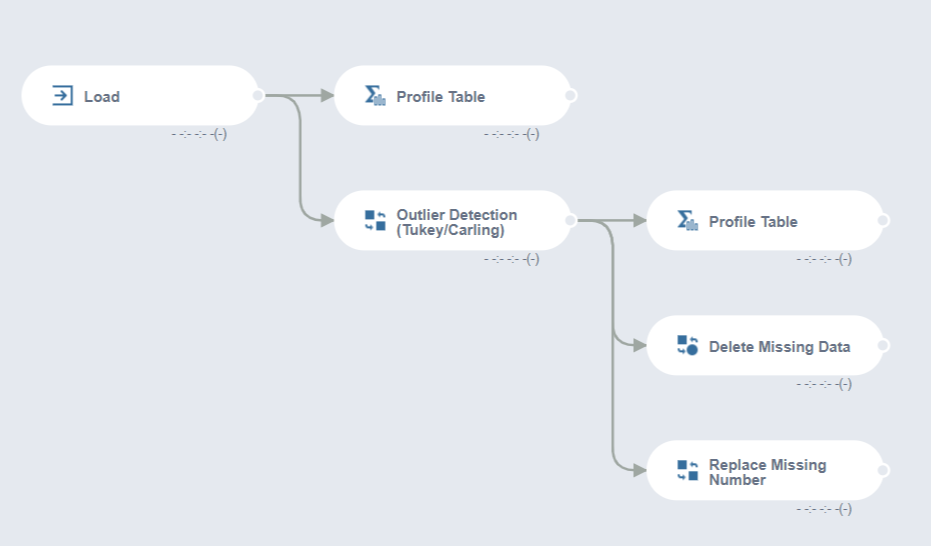
먼저, 다음과 같은 data flow 모델을 형성해줍니다.
브라이틱스를 사용하면서 항상 최고의 장점이라고 생각되는 점은
함수활용이 정말 쉽고 자유롭다는 점..
원하는 함수를 찾고, 순서대로 이어붙이기만 하면 모델링 끝!!
2. Data Load
실습 데이터 outlier_missing_txt는 이상값과 결측치 처리를 위해 생성한 데이터이며
변수 구성은 다음과 같습니다.
| 변수명 | 설명 | 데이터 타입 |
| date | 날짜 | String |
| Var1 | 변수1 | Double |
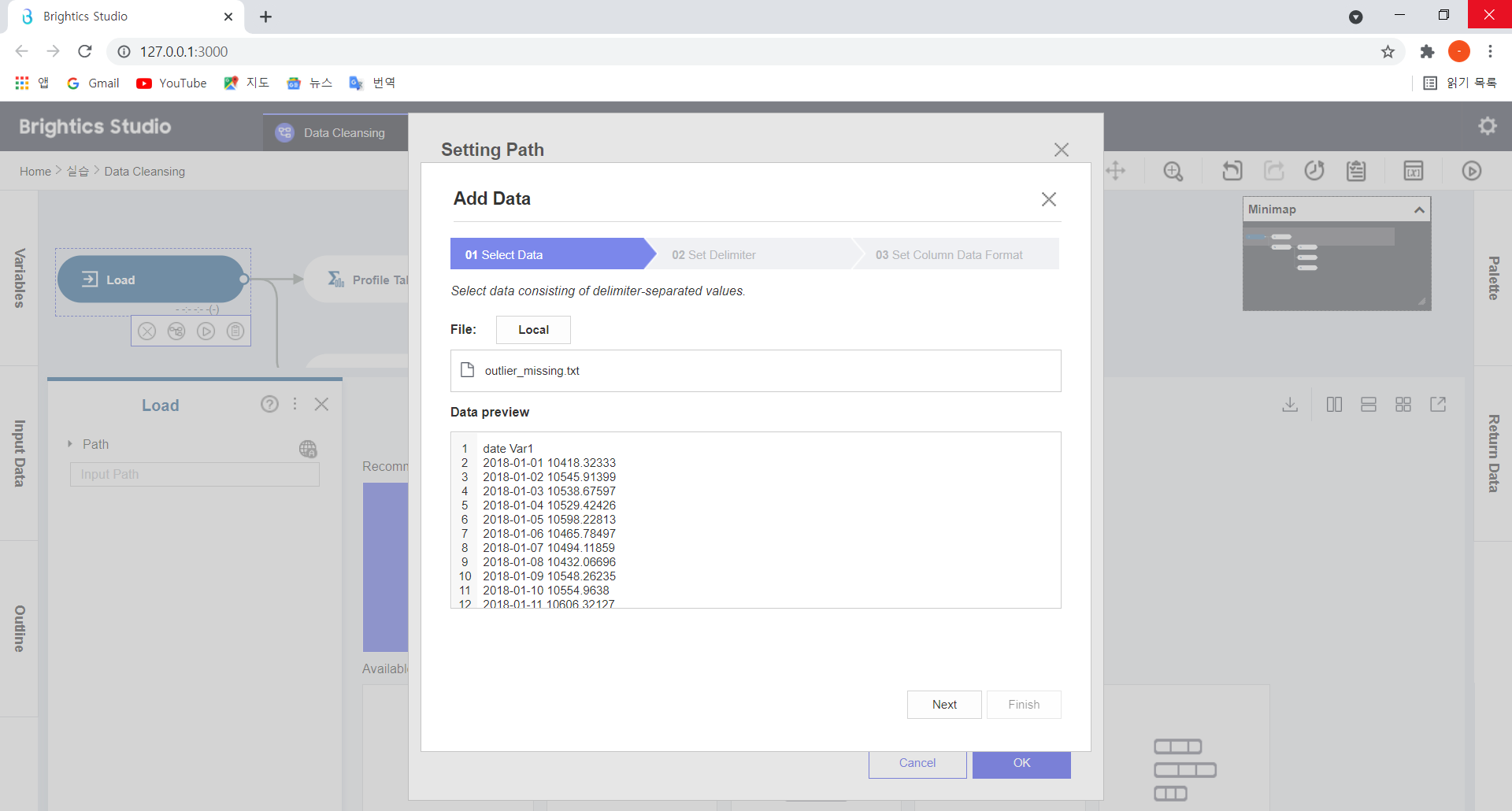
우선 Load 함수를 클릭하여 outlier_missing_txt 데이터를 선택하고,
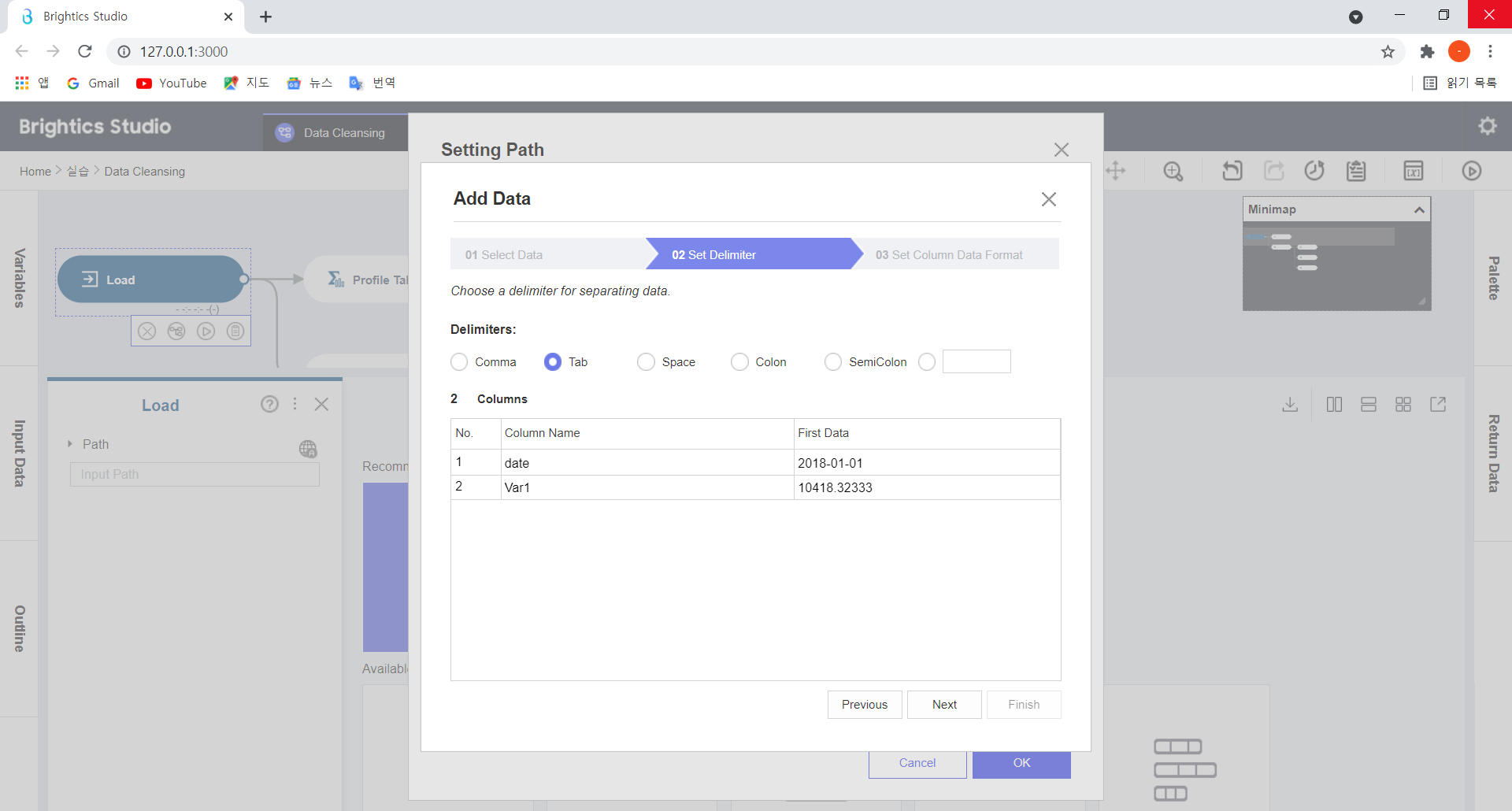
Column 구분을 위한 Delimiter(Comma/Tab/Space/Colon/SemiColon) 을 선택한 후, Next 버튼을 누릅니다.
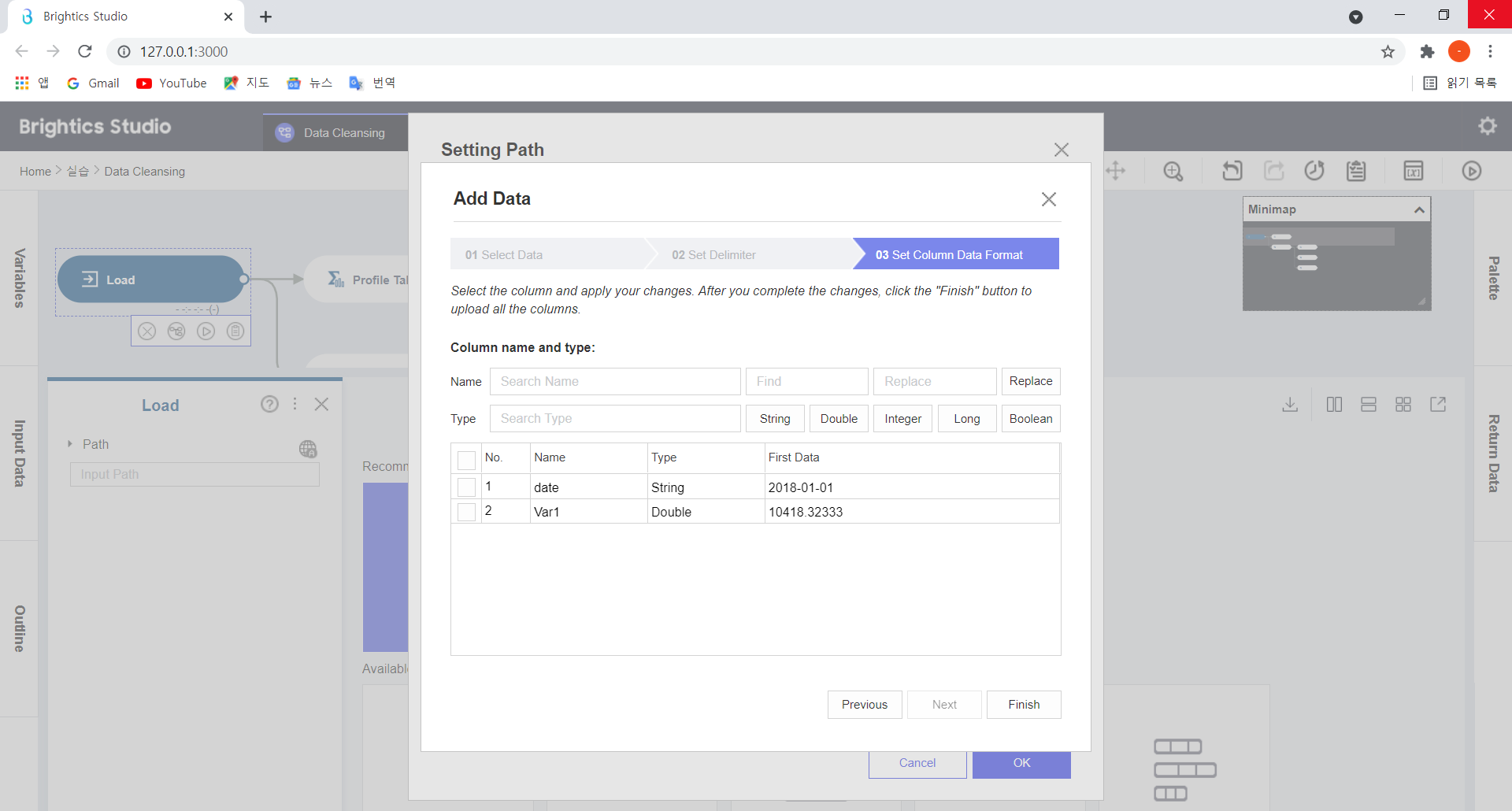
데이터 Column 별 형태를 지정한 후, Finish > Run을 누르면,
데이터 Load가 완료됩니다!
3. 데이터 요약
그 다음은, Profile Table 함수를 이용하여 데이터를 요약하고 전처리방식을 판단해보도록 하겠습니다.
Profile Table함수는
결측치 개수, 히스토그램, 고유값 개수 등 데이터에 대한 요약 정보와 변수별 상세 내용을 확인할 수 있게 해줍니다!
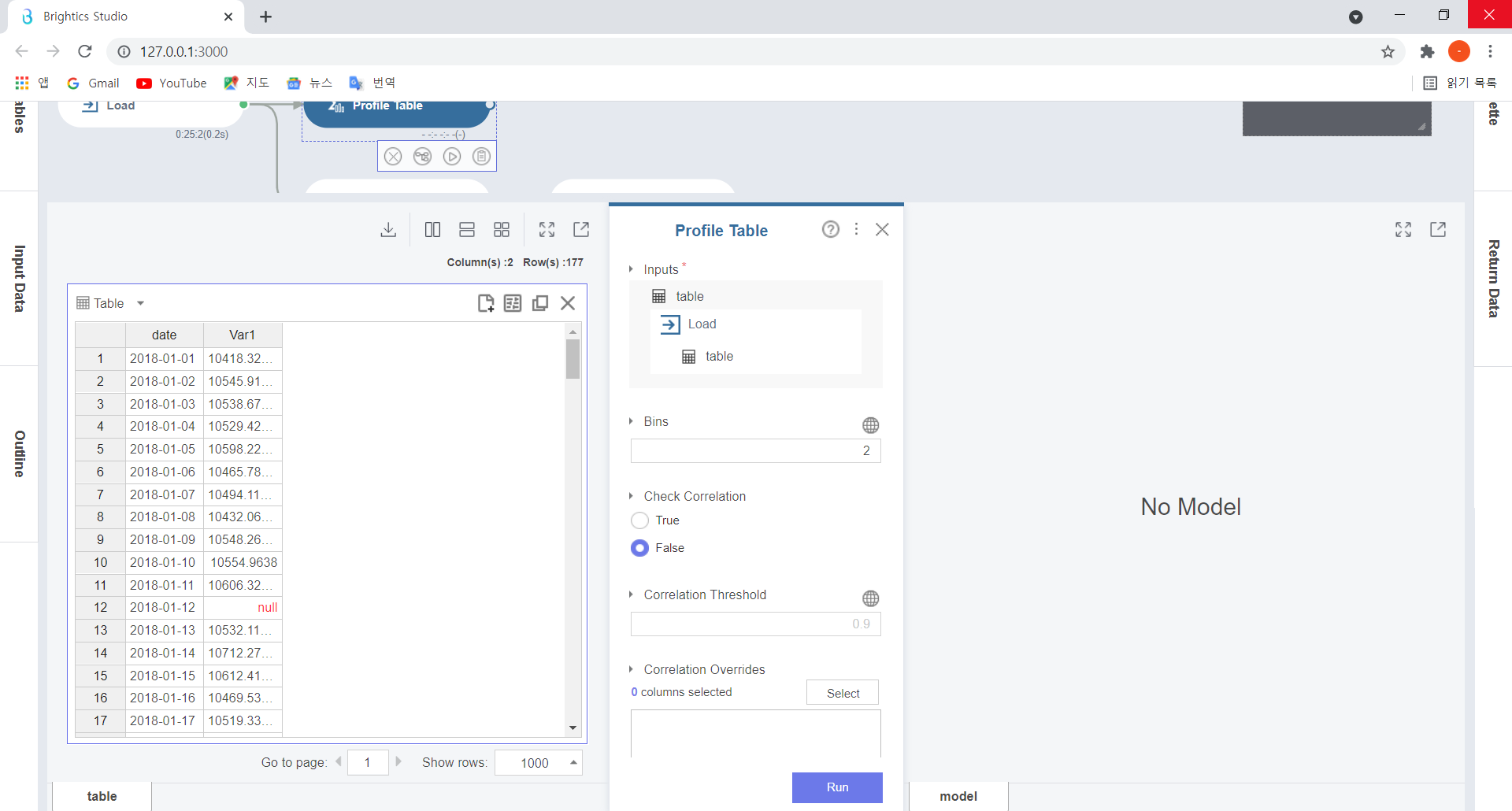
Profile table 블록의 설정창은 위와 같습니다.
Bins는 히스토그램을 그릴 때 지정하는 구간의 개수인데요, 위 table은 구간이 2개이므로, 숫자 2를 입력해줬습니다.
그 밑 Check Correlation은 수치형 변수간 상관관계를 살펴보는 설정인데요,
True로 설정할 경우, Pearson 상관계수과 Spearman 상관계수 결과가 출력됩니다!
하지만 이번 실습은 상관계수 분석과는 관계가 없으므로..pass!하고 False 상태값을 변경하지 않고 Run을 눌러주도록 하겠습니다.
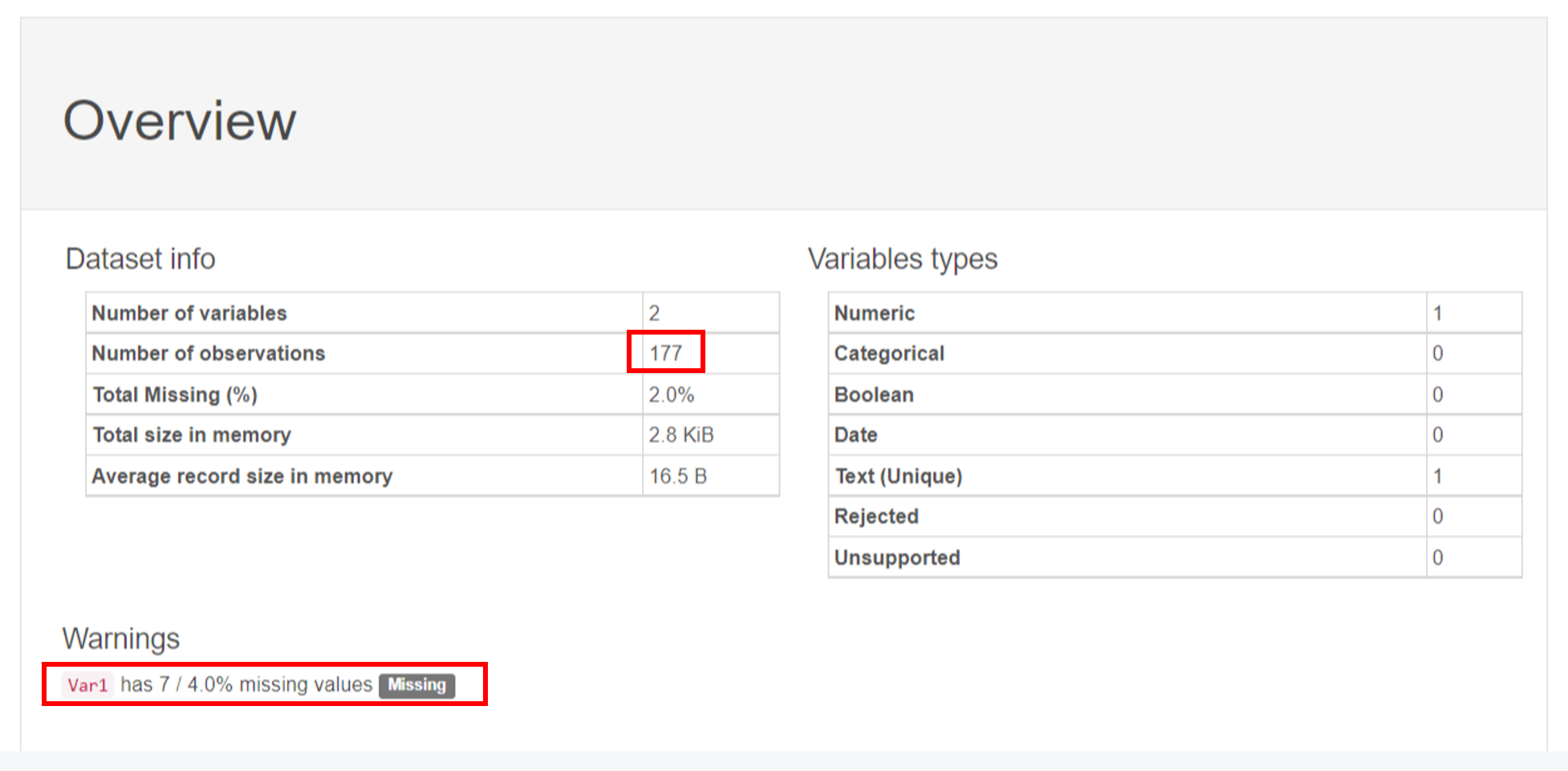
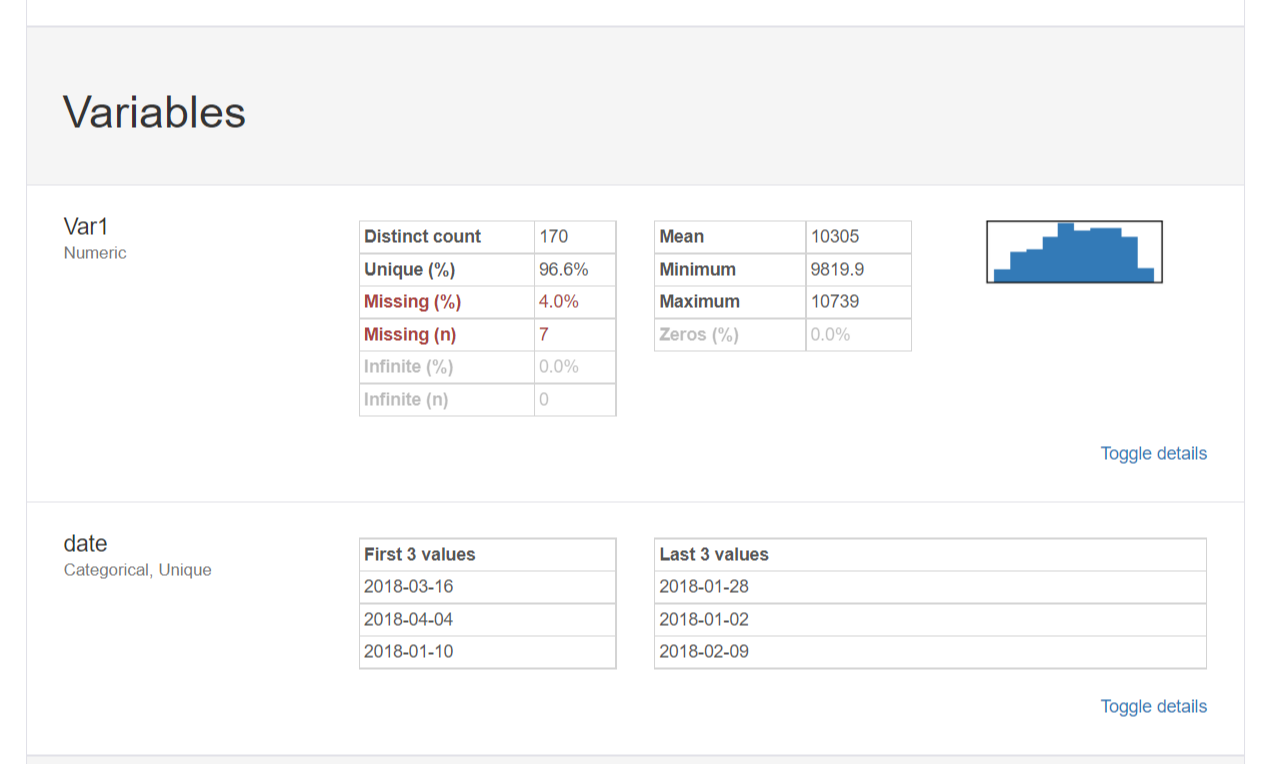
먼저, [Overview] 항목을 살펴볼까요?
총 177개의 관측치 중 결측값의 비율은 2%이고,
Var1변수는 7개의 결측값이 있는 것을 확인할 수 있었습니다!
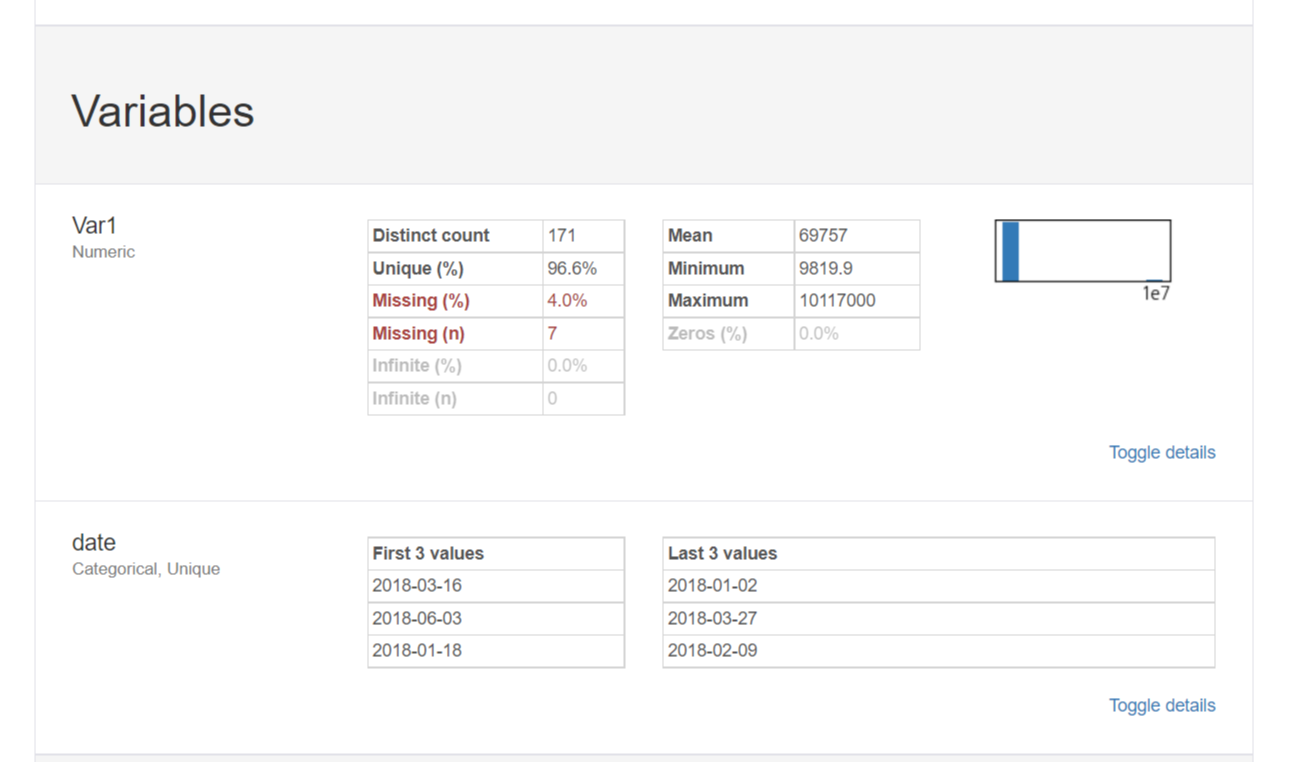
7개의 결측값이 나온 Var1항목을 다음 [Variables]항목에서 더욱 자세히 살펴보겠습니다.
대부분의 관측치와 동떨어진 이상치가 발견되었습니다!
앞서 이상치 탐지와 관련한 이론 학습에서 살펴보았듯이,
히스토그램을 통하여 이상치를 다시 한번 확인해봅시다.
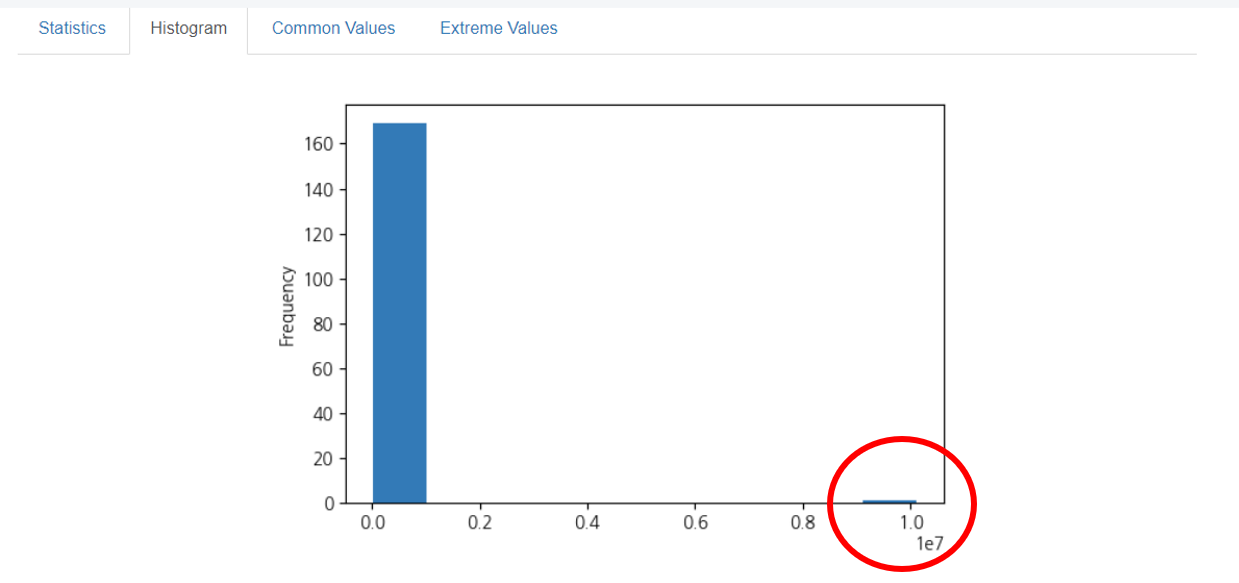
히스토그램으로 크게 확인해보니,
이상값이 더욱 눈에 띄네요!
이상치의 빈도수와 값의 크기도 확인할 수 있었는데요,
이제 이상값이 확인이 된 만큼,
이를 실제 data table에서 찾아내고 제거를 해봅시다!
4. 이상값 제거
이상값 제거는 Carling/Tukey 중 Tukey방식을 이용해보도록 하겠습니다.
앞서 이론학습에서, Tukey 방식은 경계값 1.5를 기준으로 사용한다고 했었는데요,
이를 기본값으로 설정하여 이상값을 제거해보겠습니다.
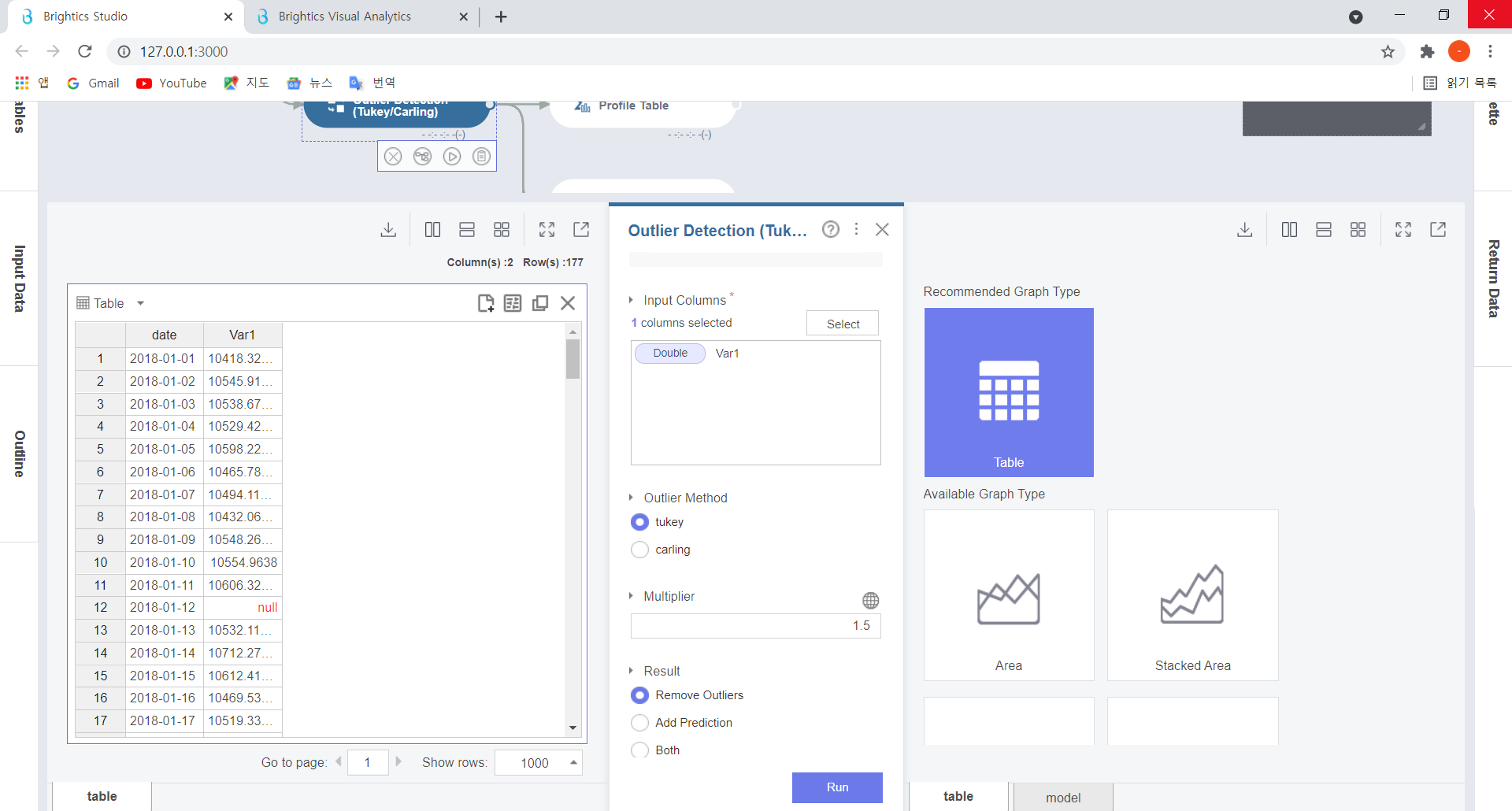
Outlier Detection(Tukey) 설정 항목을 살펴보겠습니다.
Input Columns 항목에는 이상치가 포함된 Var1을 select하여 넣고,
Outlier Method인 Tukey 방식을 선택한 후,
Result 항목에서는, 본 함수사용의 목적인 Remove Outliers 를 선택하고
Run을 눌러주세요!
(Multiplier 항목에는 경계값 1.5를 입력해주세요.)
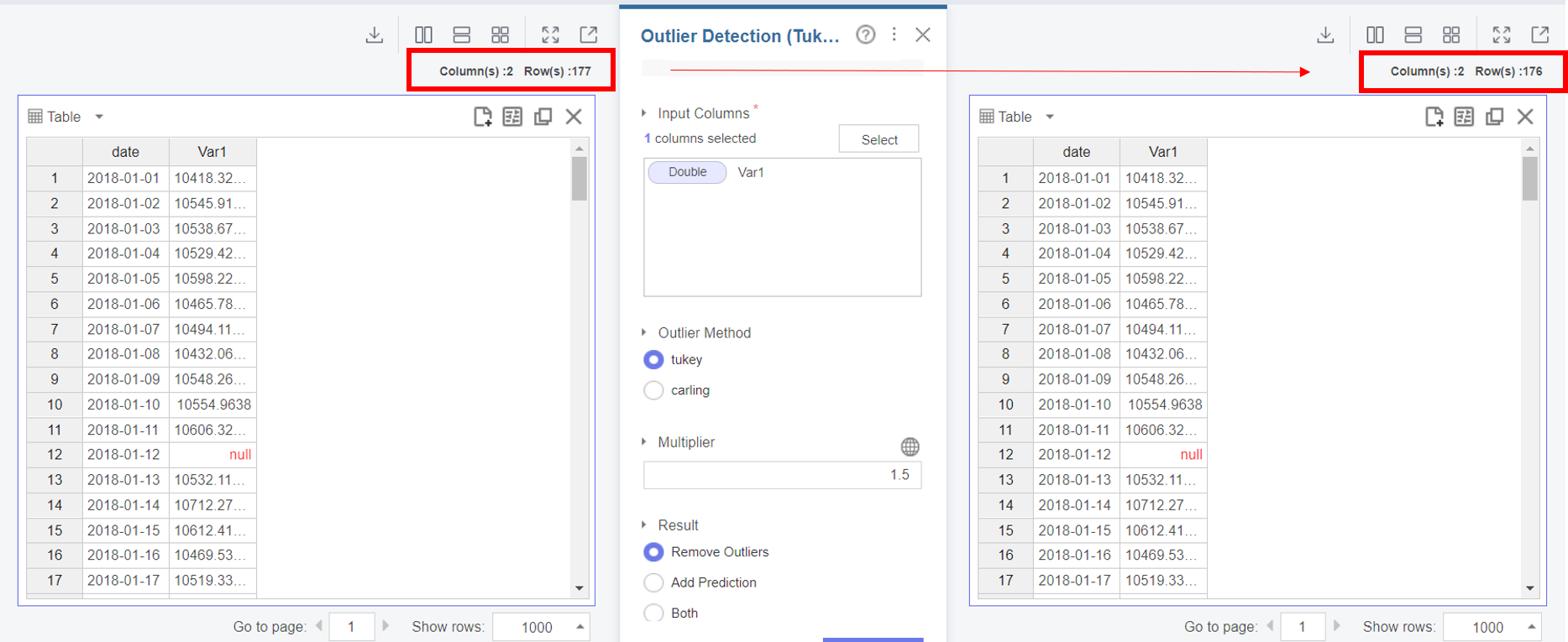
이전과 비교해보면,
이상값이 포함된 1개의 행이 삭제된 것을 알 수 있습니다!
(177개 → 176개)
5. 데이터 요약하여 이상값 제거 확인
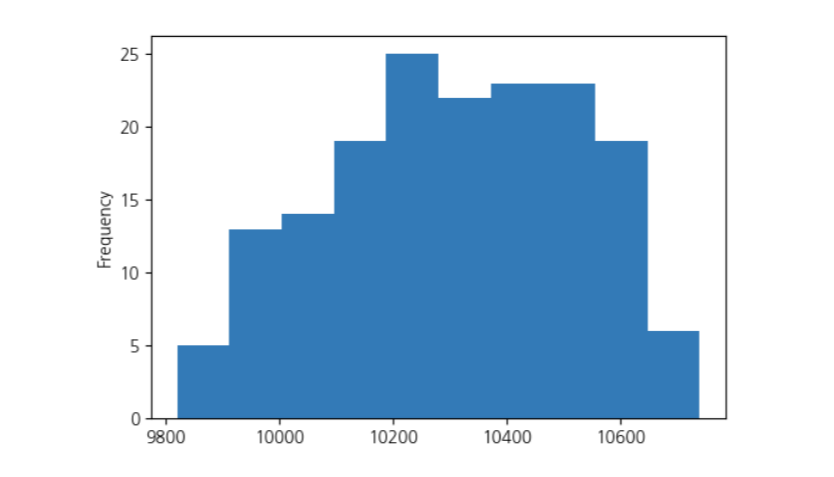
이렇게 이상값이 제거된 데이터를 다시 Profile Table 함수로 요약해보면,
관측치가 전과는 다르게 대체로 종모양을 띠고 있음을 확인해볼 수 있습니다.
6. 결측값 처리
이상값을 제거했으니, 이제 결측값을 처리하는 단계만 남았네요!
결측값을 처리하기 위해서는 해당 결측값을
(1) 제거하거나
(2) 다른값으로 대체해야 합니다.
하나만 살펴보기는 아쉬우니,
결측값 제거 / 대체를 모두 실행하고 결과를 확인해보도록 하겠습니다!
6-1. 결측값 제거
결측값을 제거하기 위해서는 Delete Missing Data 함수를 활용합니다.
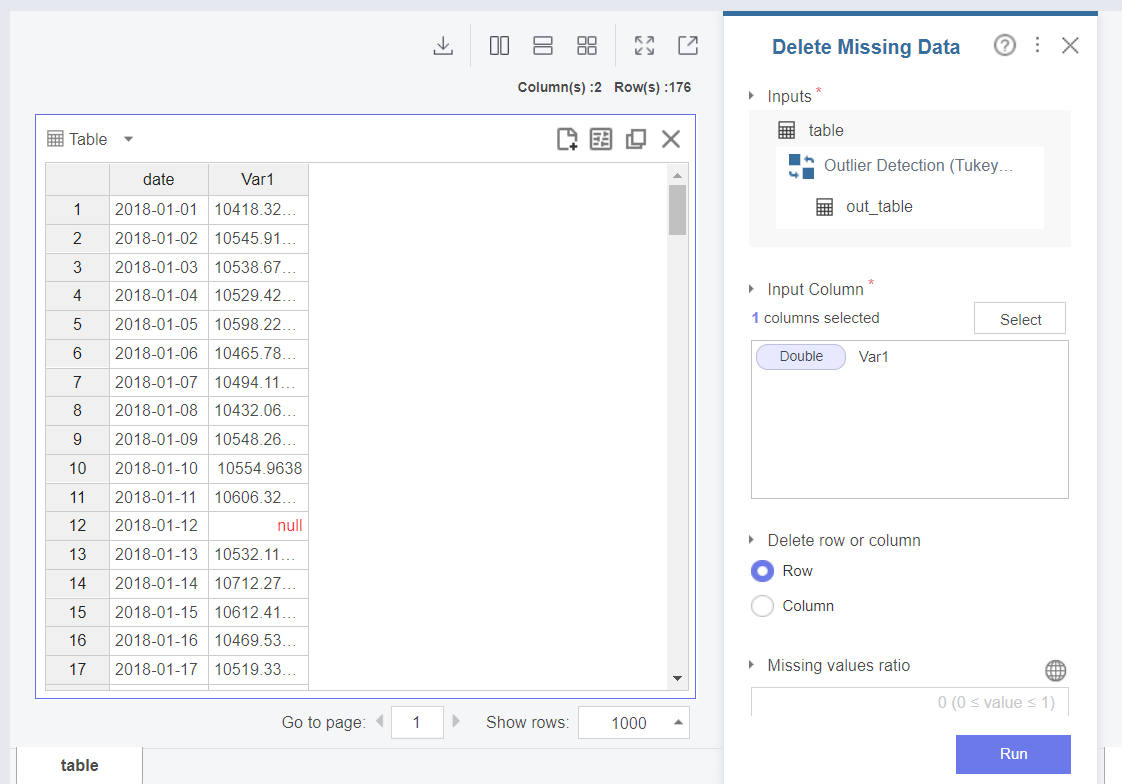
Delete Missing Data 설정블록에서는
Input Column 항목에 결측값이 존재하는 Var1을 선택하여 넣고,결측값이 존재하는 행(Row)을 제거합니다.
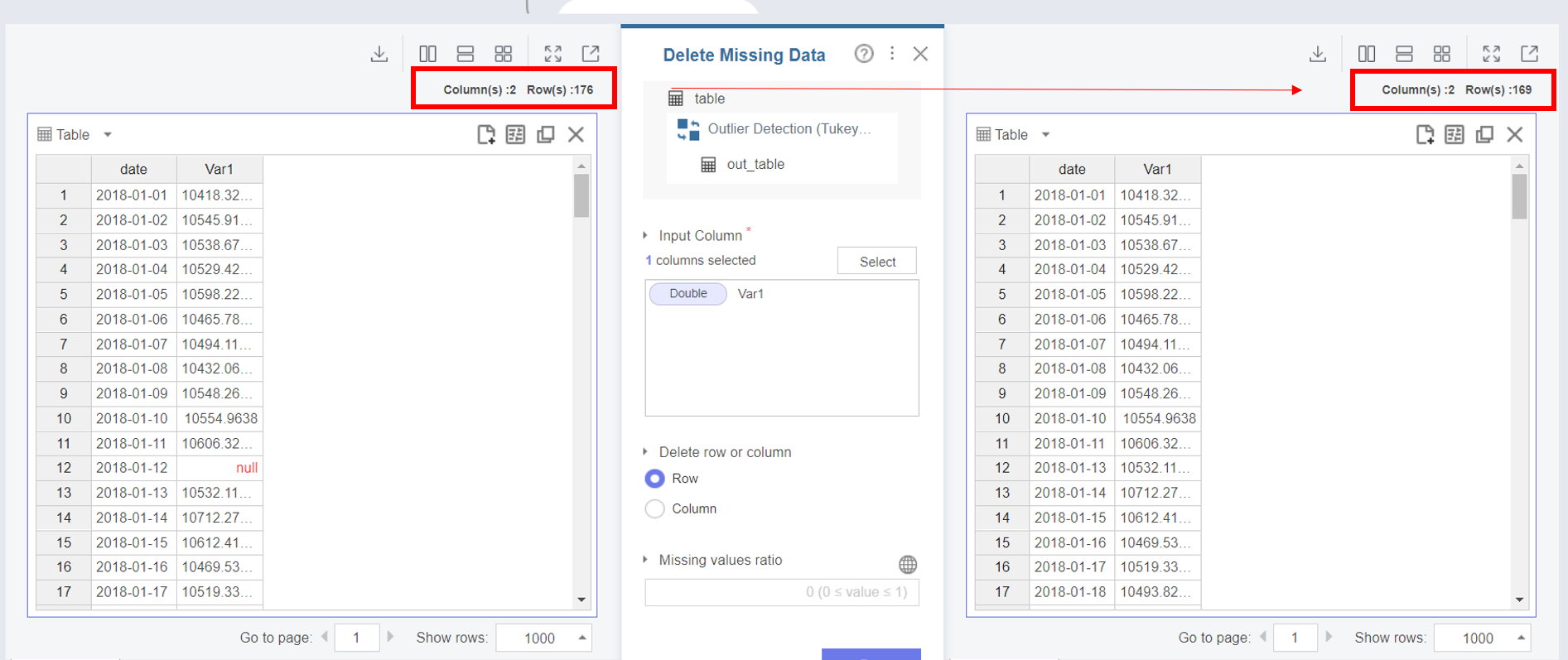
결과를 살펴보면,
행의 개수가 176개 → 169개로 줄어든 것을 확인할 수 있습니다.
결측값 7개가 제거 되었네요!
6-2. 결측값 대체
결측값을 대체하기 위해서는 Replace Missing Number함수를 활용합니다.
Replace Missing Number 함수는 결측값이 발생한 숫자형 타입의 변수에 대해
평균, 중간값 등으로 채워주는 함수인데요,
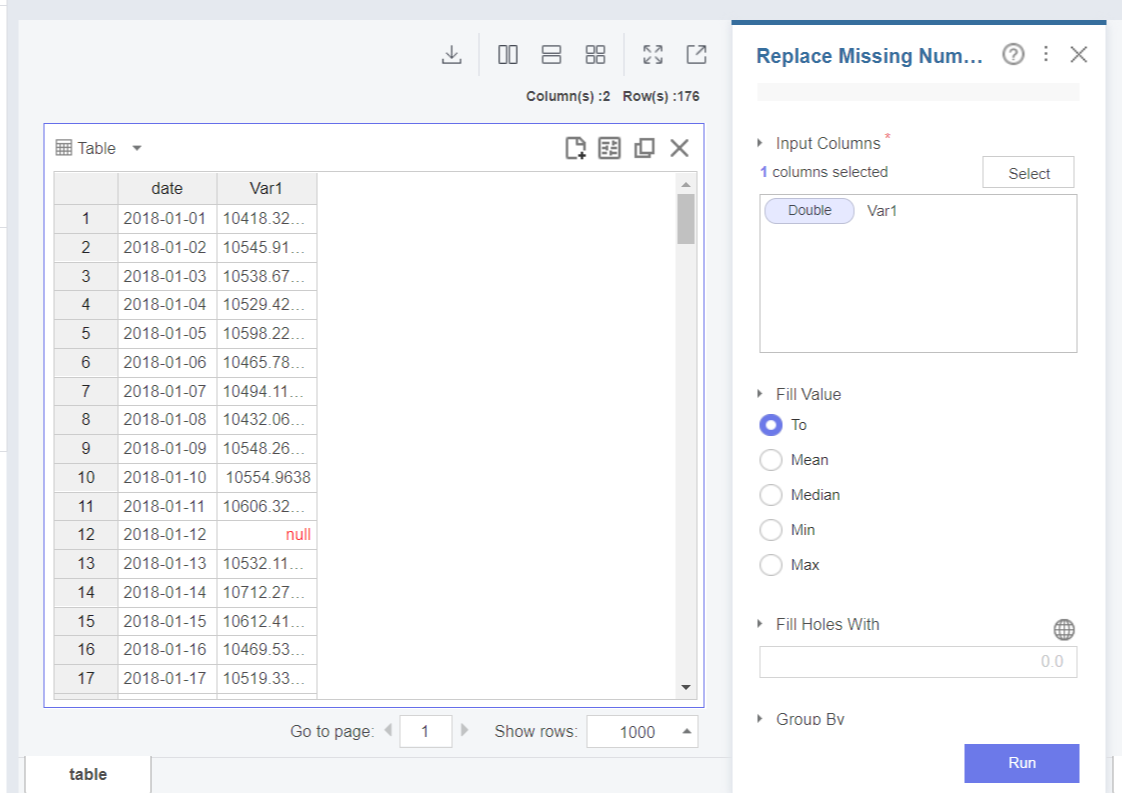
앞의 함수 설정항목들과 마찬가지로 Input Columns에 결측값이 포함된 Var1을 넣고,
Fill Value 항목에 대체하고자 하는 변수의 값을 선택하면 됩니다.
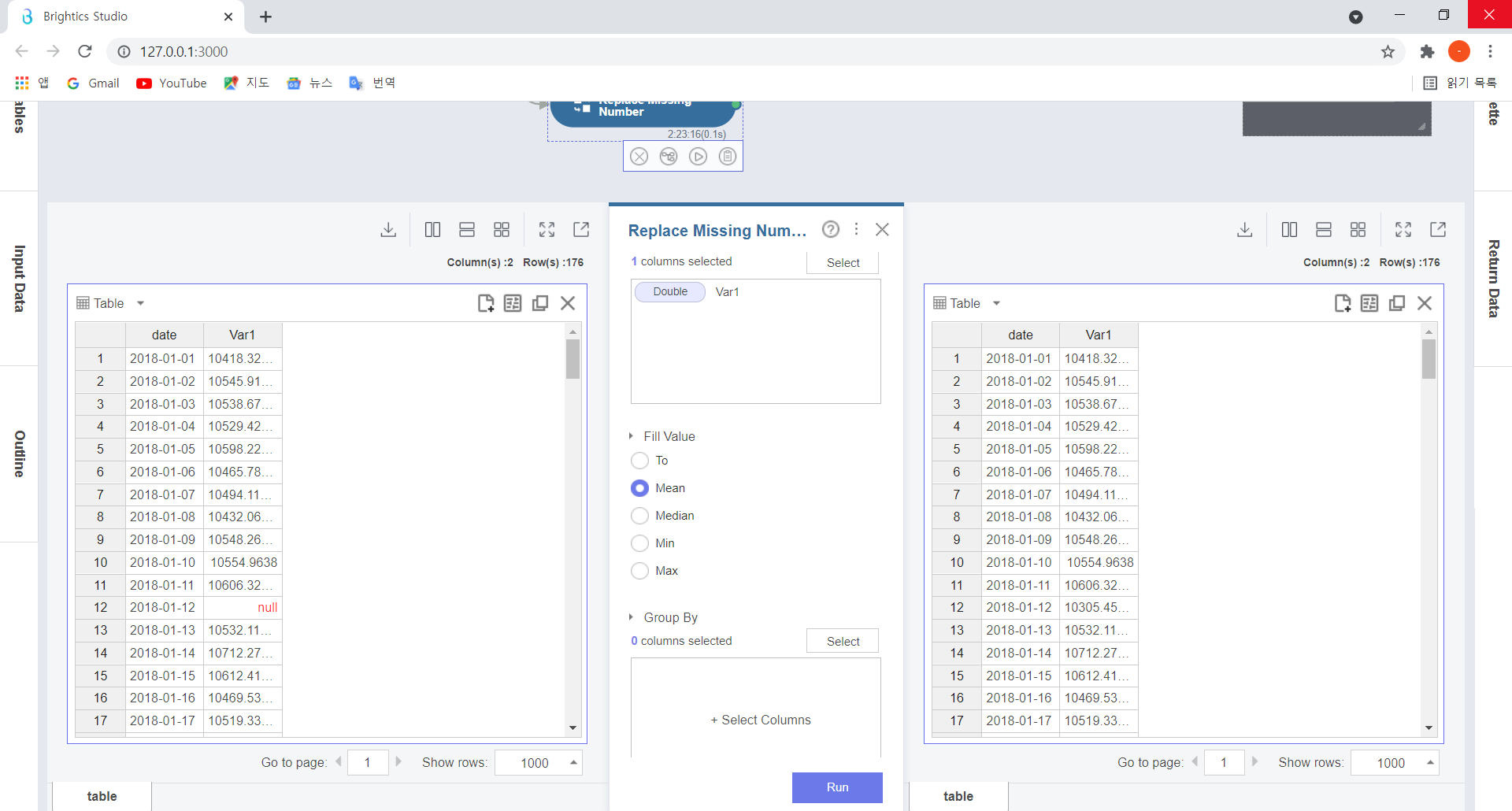
저는 변수의 평균값 Mean을 선택하여 결측값을 대체했습니다.
※ 결측값을 대체할 때는 결측값이 존재하는 값의 위치나 범위 등을 확인한 후,
분석가의 판단에 따라 정상변수들과의 편향(bias)이 최소화되도록 Means, Median, Min, Max 등의 다양한 변수값으로 대체해야 합니다!
이렇게 Data cleansing을 통해 이상값과 결측값의 처리과정 실습을 마치도록 하겠습니다!
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.