[삼성 SDS Brightics] 데이터 전처리 학습② - 데이터 정제(data cleansing) 실습(feat. Titanic csv.)

지난 포스팅에서는
https://yeenn-db.tistory.com/3
[Brightics] 데이터 전처리 학습① - 데이터 정제(data cleansing) 이론 및 실습
안녕하세요! 드디어 브라이틱스 서포터즈의 2번째 미션이 시작되었습니다. 이번 개인 미션은 공개 dataset을 이용하여 Brightics Studio를 활용한 실습을 본격적으로 진행해보는 것인데요, 앞으로 약 3
yeenn-db.tistory.com
데이터 전처리 학습과 관련한 기본 이론과 기초 실습과정을 다루어봤는데요!
이번 포스팅에서는
Kaggle의 유명 dataset인 Titanic.csv를 이용하여 데이터 전처리 심화학습을 진행해보도록 하겠습니다.
Kaggle이란?
빅데이터 분석에 관심이 있는 분들이라면 한 번쯤 들어봤을 Kaggle은 2010년 설립된 예측 모델 및 분석대회 플랫폼인데요, 기업 및 단체에서 데이터와 과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁하는 곳입니다.
Kaggle 의 다양한 공개 dataset 중 하나인
Titanic dataset은
https://www.kaggle.com/c/titanic/data
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
위 링크에서 다운로드 가능합니다!
타이타닉호의 탑승자 정보가 담겨있는 Titanic dataset은 train.csv와 test.csv 로 이루어져 있는데요,
이번 실습은 데이터 cleansing과정을 위주로 진행할 예정이기 때문에,
생존자 정보가 배제된 test.csv 파일을 사용하도록 하겠습니다.
1. Titanic Test data 설명
| 변수(Variable) | 정의(Definition) | Key |
| pclass | Ticket class | 1=1st, 2=2nd, 3=3rd |
| sex | Sex | |
| age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | #of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Porked of Embarkation | C=Cherbourg, Q=Queenstown, S=Southampton |
* Row(행) 418개, Column(열, 변수) 11개 구성
- pclass: 티켓의 등급 (1=1st(Upper)/=2nd(Middle)/3=3rd(Lower))
- sex: 탑승객의 성별
- age: 탑승객의 나이
- sibsp: 타이타닉호에 탑승한 형제/배우자의 수
- parch: 타이타닉호에 탑승한 부모/자녀의 수
- ticket: 티켓 번호
- fare: 탑승객 요금
- cabin: 객실 번호
- embarked: 기항지 위치 (C=Cherbourg/Q=Queenstown/S=Southampton)
지금까지 test dataset을 살펴보았는데요,
이제 결측치와 이상치를 처리하기 위한 브라이틱스 데이터 플로우 모델을 구성해보겠습니다.
2. Data Flow Model 구성

먼저, 실습에 사용할 함수들을 포함한 Data Flow Model을 다음과 같이 구성해줍니다.
3. Data Load

먼저, Load함수를 통해 train.csv 파일을 불러옵니다.
중간중간 'null'표시가 되어있는 결측값들이 보이네요!
4. Data 정보 확인
앞서 실습에서도 이용했었던
데이터 요약 함수 Profile Table을 통해 결측치와 변수별 상세내용들을 확인해보도록 하겠습니다.

Bins에 열 값 10을 넣어주고,
Correlation Overrides 항목에 모든 변수를 넣은 후 Run을 눌렀습니다.

데이터 요약 Overview를 살펴볼까요?
총 418개의 관측치 중 결측값의 비율은 4.5%로 나타났네요!
age 변수에는 86개의 결측값이, ticket 변수에는 122개의 결측값이 존재하고,
Cabin변수는 중복 수치가 낮음을 알 수 있었습니다.
(*High Cardinality=중복도 낮음 / *Low Cardinality=중복도 높음)
해당 변수들을 조금 더 자세히 살펴보겠습니다!
결측값이 나타난 변수별 세부 요약정보들을 확인해보면,
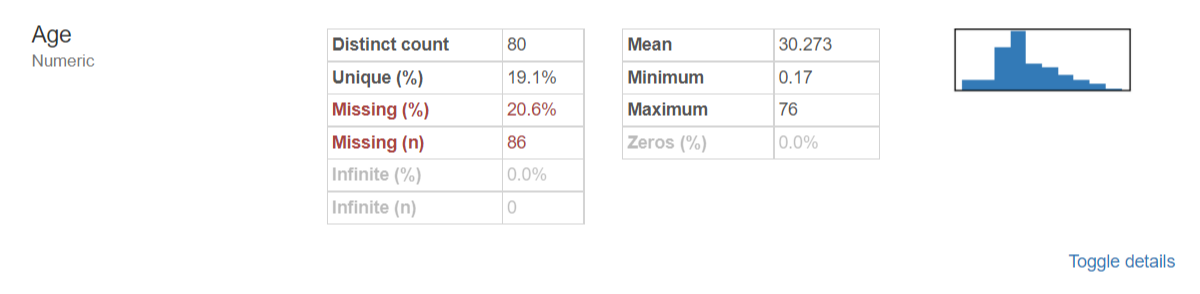


위와 같음을 확인할 수 있습니다!
Fare변수에도 결측치가 1개 존재하고 있었네요!
5. 이상값 탐지 및 제거

그 다음은, Outlier Detection 함수의 turkey방법을 통해 Outliers(이상치)를 제거해보겠습니다.
소수의 이상치가 발견된 age변수와 ticket변수를 선택해 넣고,
Multiplier에 기준값 1.5를 넣어준 후 Remove Outliers 항목을 선택하여 Run을 누릅니다.
※ 여기서 잠깐! Turkey 방법이란?
Q3 + 1.5배의 사분위범위를 초과하거나, Q1 - 1.5배의 사분위범위 미만인 값을 이상치라고 정의하는 방법
→ 이상값을 제거한 후, age변수와 ticket변수의 box plot은 어떤 변화를 보일까요?


우측의 결과 화면에서 Chart settings를 클릭한 후,
Age변수 → X-axis: Column name / Y-axis: age
Ticket변수 → X-axis: Column name / Y-axis: ticket
로 변수를 변경해줍니다.
- Age 변수의 Box plot 변화 (전 → 후)


age 변수의 이상치(outlier) 2개가 제거된 모습을 확인할 수 있습니다!
- Ticket 변수의 Box plot 변화(전 → 후)


마찬가지로, ticket변수의 이상치(outlier) 1개 또한 잘 제거가 되었네요!
6. 결측값 탐지 및 제거
1) Age 변수와 Ticket 변수의 결측값 처리
이상값을 처리했으니, 이제 결측값을 처리하는 단계가 남았습니다.
결측값을 제거할 것인지, 또는 대체할 것인지에 따라서
Delete Missing Data 함수와 / Replace Missing Number 함수가 쓰일텐데요,
앞서 데이터 요약에서도 살펴보았듯이 age 변수와 ticket 변수의 결측값 개수가 상당하기 때문에..
([Overview] 참고)

결측값을 대체해주도록 하겠습니다!
Replace Missing Number 함수를 사용해야겠죠?

결측값을 대신 채울 값으로, age 변수와 ticket 변수의 평균(Mean)을 선택한 후, Run을 눌렀습니다.
그럼 이제 남은 Fare 변수의 결측값을 처리해보겠습니다!
2) Fare 변수의 결측값 처리
Fare 변수의 결측값 개수는1개(153row에 위치)였는데요,이 경우는 과감하게 결측값을 삭제해주는 편이 좋을 것 같습니다.Delete Missing Data 함수를 사용해줍시다!

Delete 함수를 통해 fare 변수의 결측값의 행(Row)을 제거했습니다!

모든 결측값이 처리되었습니다!
이상값과 결측값의 처리는 이렇게 마무리가 되었는데요!
마지막으로, Brightics의 대체 함수 중 문자값에 오류가 있거나, 긴 문자열을 다른 문자로 대체할 때 사용하는
문자열 대체 함수(Replace String Variable)를 사용하여
sex 변수를 대체해보겠습니다.
+7. 문자열 대체

함수 설정항목에서, 성별 변수 Sex column을 추가한 뒤,
전체 변수가 아닌 일부 변수를 바꿀 것이기 때문에 Replace Mode에서 Part를 선택해주세요!
Target string 항목에는 바꾸고자 하는 원래 string 변수의 이름(female)을 넣고,
Replace String 항목에 대체어 F를 넣어줬습니다.

Run을 누르면, target_string 항목 하에 다음과 같은 빈칸이 나오는데요,
원래 문자열 변수의 이름(female)을 넣어주시면 됩니다.
이렇게 대체하고 나면, 이후 성별과 관련된 분석을 할 때 결과가 더 한 눈에 들어올 수 있겠네요!
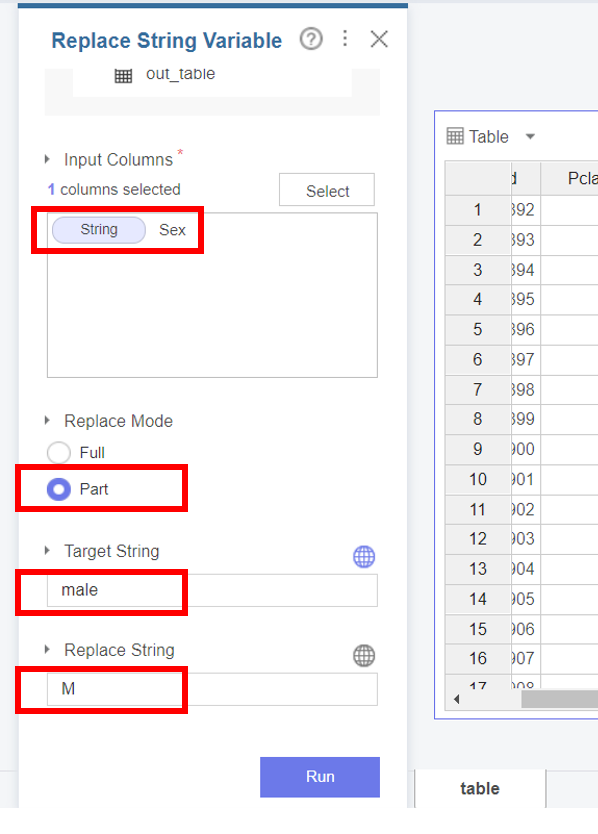

male 변수도 앞과 같은 과정을 거쳐
male → M으로 변환해주었습니다!

female → F,
male → M
으로 문자열 변수가 성공적으로 대체되었습니다!
이렇게 데이터 정제와 관련된 심화실습을 마치도록 하겠습니다.
본격적인 데이터 분석에 들어가기 앞서, 정확한 분석결과를 위한 이상치와 결측치 처리과정은 매우매우 중요한 단계입니다!
이상치와 결측치는 무조건 제거해서도 좋은 것이 아니고, 무조건 평균값/중간값 등으로 대체해서도 좋은 것이 아닙니다.
변수의 분포형태와 중요도등을 고려하여 신중하게 가공해야 정제된 좋은 dataset을 얻을 수 있다는 점이
이번 실습에서 가장 중요하게 배워야 할 점이라고 생각합니다.
그럼 다음 포스팅으로 찾아뵐게요!
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.