
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 분석모델링
- 데이터분석대외활동
- 삼성sds
- 회귀모형평가
- Brightics서포터즈
- houseprice
- 데이터전처리
- 브라이틱스
- Kaggle출전
- associateDS
- 골목상권데이터분석
- 코딩없이데이터분석
- Brightics
- 모델링
- 삼성SDSBrightics
- IT멘토링
- ProDS
- 삼성자격증
- Datascientist
- SDSBrightics
- EDA
- samsungsds
- 브라이틱스서포터즈
- 데이터분석
- kaggle
- 서울시상권분석
- 상권배후지
- 브라이틱스데이터분석
- AdSP
- BrighticsStudio
- Today
- Total
Database for Everything
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_데이터 전처리① 본문
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_데이터 전처리①
Yeenn 2021. 9. 6. 23:48
안녕하세요! Brightics 서포터즈 yeenn입니다.
ProDS시험도 끝났겠다
(합격도 했겠다!)
개강 첫 주라 비교적 여유로운 한 주를 보내고 있는데요,
정말 오랜만에 여유있게 포스팅을 작성하는 것 같아 기분이 좋습니다ㅎㅎ
지난 주 개인분석 프로젝트 미션의 주제 선정과정을 담은 포스팅을 작성했었는데요,
https://yeenn-db.tistory.com/29
[삼성 SDS Brightics] Brightics 개인분석 프로젝트 시작! _ 공공데이터 확보, 그리고 주제 선정
안녕하세요! Brightics 서포터즈 yeenn입니다. ProDS 시험도 끝났고, 바람이 부는 선선한 가을이 오면서 드디어 찾아온 개.강. ..... 다행히도 팀분석프로젝트 + 튜토리얼 영상제작 미션까지 무사히 마
yeenn-db.tistory.com
다행히도 주제 변경 없이 위 주제 그대로 프로젝트를 진행하게 되었습니다.
주제 선정과정이 궁금한 분들은 위 포스팅을 참고해주세요!
이번 포스팅을 비롯한 약 3주간의 포스팅은 데이터 전처리와 관련한 분석내용을 담을 예정입니다!
Data Load

Brightics 에서는 data를 load할 때
File명을 알파벳과 숫자, 그리고 지정된 기호로만 지정해야 하는데요,
서울시 포탈에서 내려받은 데이터이다보니 File명이 모두 한글로 지정되어있어
아래와 같이 영문명으로 파일명을 변경해주었습니다.

가끔 Brightics에서 변수명이 한글로 지정된 데이터를 load하다보면
변수명의 글자가 깨진 채로 나타나는 오류가 발생하는데요,
이를 해결하기 위해 UTF-8로 인코딩 형식을 변경하여 csv파일을 저장해주었습니다.

아직 끝나지 않은 Load 과정...!
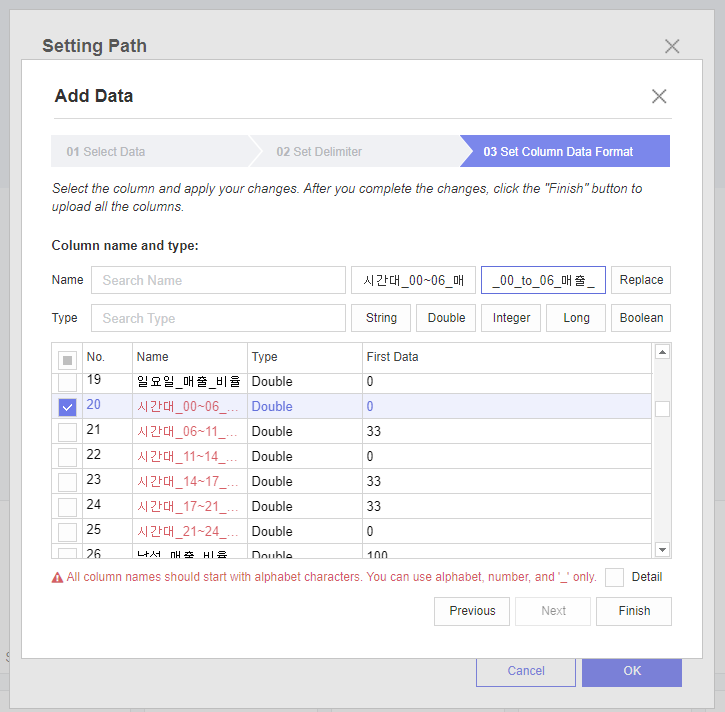
UTF-8인코딩을 통해 변수명을 한글로 load하는데에는 성공했지만, 일부 변수명에
지정되지 않은 기호 '~' 가 들어가 있어 '_to_'로 대체해주었습니다.
하지만 동일한 오류의 변수들이 많아 하나씩 대체하기는 너무 시간이 오래걸리더라구요.

그래서!
대체해야할 기호가 포함되어 있는 변수들의 공통단어로 필터링 한 후, Replace 버튼을 이용해
한번에 기호를 대체해주었습니다.
결과는 Load 성공!
Filter함수로 년도별 데이터 추출
서울 열린데이터 광장이 제공하는 골목상권 데이터는 대부분 2014-2021년까지의 데이터 자료를 포함하고 있었는데요,
기존 계획서에서는 2016년-2021년까지의 데이터를 모두 다루려고 했지만,
데이터를 쭉 확인해본 결과
-분석해야 할 데이터의 수가 방대하고,
-오래된 데이터일수록 유실된 데이터가 많았고,
-코로나 전후의 상황을 파악할 수 있는 가장 최근의 데이터를 반영하는 것이 정확하다
는 생각에
2019년과 2020년 두 해의 데이터를 비교하며 다루기로 결정했습니다.


Load한 상권과 상권배후지의
아파트, 집객시설, 점포, 직장인구, 상주인구, 추정매출, 소득소비 데이터를 Filter함수를 통해 2019년과 2020년 데이터로 필터링해주었습니다.
이후 EDA 과정에서 두 해의 데이터를 시각화를 통해 비교하여 살펴보도록하겠습니다!
그러던 중 발견한 사실,,

상권배후지-점포 데이터는 2019년까지 밖에 없어서 상권-점포 데이터만 우선 불러왔습니다!
점포 데이터를 어떻게 살릴지는 이후 전처리 과정을 더욱 진행하면서 살펴봐야할 것 같아요.

필터링을 마친 후 함수 블록의 모습인데요
Load한 데이터셋의 개수가 많아서 생각보다 map 내의 함수블록이 길어졌어요..ㅎㅎ


크게 보면 위와 같습니다!
Statistic Summary, Profile Table로 결측치 확인


그 다음은 결측치를 비롯한 요약통계량을 확인하기 위해
statistic summary 함수를 불러와 필터링한 데이터에 이어붙였습니다.
앞서 언급했듯이 Load한 데이터의 개수가 정말 많기 때문에 함수블록 복제기능을 이용해도 노가다가 되는 상황...
이럴 때 사용할 수 있는 Brightics의 클립보드 기능!
복사한 함수 블록들을
2개-4개-8개로 점점 늘려가며 클립보드에 옮긴 후 필요한 개수만큼 그대로 불러와 사용하여
금방 statistic summary 함수 연결을 끝냈습니다!
빠르다 빨라 브라이틱스...bbb

골목상권의 아파트 데이터부터 요약통계량을 확인했습니다!
확인해보니, 아파트의 면적과 가격 변수에서 상당수의 결측치가 있는 것으로 확인이 되었는데요,
숫자로만 확인하니 결측치의 비율이 어느정도인지 잘 파악이 되지 않아 Profile table함수를 이용해 결측치의 비율을 살펴보았습니다.


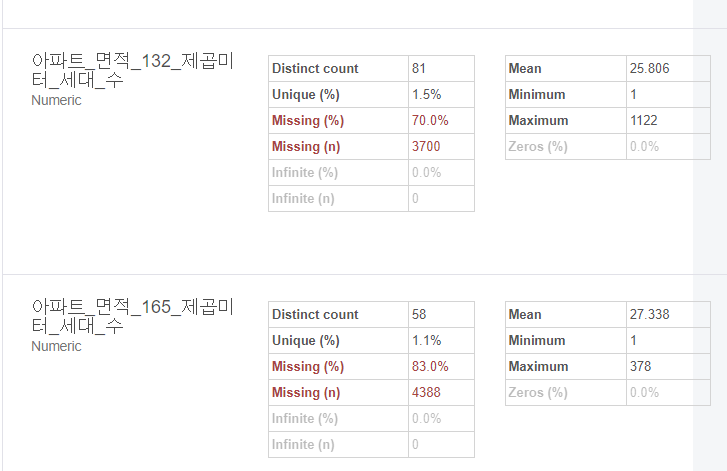
profile table을 사용해서 결측값이 value의 50%이상 차지하는 변수들을 확인한 후,

수치형 변수의 결측치를 대체할 수 있는 함수인 Replace Missing Number 함수를 이용하여
Fill Value에 평균값 Mean을 지정한 후, 대체해주었습니다.

결측치의 비율이 높지 않았던 다른 아파트 가격변수와 면적변수는 Delete Missing Data를 사용하여 결측치를 모두 제거해주는 방식을 선택했습니다.
결측치가 포함된 왼쪽의 table과 오른쪽의 table의 row개수의 차이, 보이시나요?
위와 같은 방법으로 Load한 데이터 중 결측치가 발견된 데이터들은 결측치를 평균값으로 대체하고 제거하는 방법으로 결측치를 처리해주었습니다.
[결측치 처리해준 변수]
상권-아파트
상권-집객시설
상권배후-집객시설
상권-점포
결측치를 적절한 값으로 대체하고 제거하는 것은 온전한 분석가의 몫이기 때문에
분석에 꼭 필요한 데이터를 잘 정제하는 능력이 정말 중요한데요,
위 데이터셋에서는
기준비율값을 30%로 잡고
30% 이상 -> 평균대체
30% 미만 -> 제거
의 방법을 사용하여 결측치를 처리해주었습니다.
Bind Row Column을 사용한 데이터 결합

추정 매출 데이터의 경우, 년도별로 따로 정리가 되어있었기 때문에,
상권 추정매출 데이터와
상권배후지의 추정매출 데이터별로
년도를 기준으로 Bind하여 정리해주었습니다.

연도가 포함된 행을 기준으로 Bind한 함수 블록은 위와 같습니다!
다음 포스팅에서는 추가적인 데이터 전처리 및 EDA가 진행되는 과정을 담을 예정입니다!
계획한 대로 분석이 잘 이루어질 수 있도록 Brightics를 요리조리 잘 활용을 해봐야겠어요..!!
또 막간을 이용한 홍보...
코딩없이 Kaggle 대회를 나갈 수 있다고?!
저희 Brightic3가 만든 두 번째 팀프로젝트 영상도 많은 시청바랍니다!!!

↓
코딩 1도 모르는 사람도 프로 kaggler로 만들어준다는 바로 그 강의! (feat. 만능 Brightics)
Brightics Studio를 이용해 Kaggle competition에 도전하는 과정을 인터넷 강의 형식의 영상으로 제작했습니다. 영상을 통해 Brightics 사용 튜토리얼을 제공하고, 분석 과정에서 발생하는 다양한 문제점 해
youtu.be
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.



