
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SDSBrightics
- 브라이틱스
- 데이터전처리
- Datascientist
- 상권배후지
- 데이터분석
- 삼성자격증
- AdSP
- kaggle
- 삼성SDSBrightics
- samsungsds
- ProDS
- 데이터분석대외활동
- IT멘토링
- 골목상권데이터분석
- houseprice
- 서울시상권분석
- BrighticsStudio
- 삼성sds
- 코딩없이데이터분석
- Brightics서포터즈
- Kaggle출전
- 분석모델링
- 회귀모형평가
- associateDS
- 모델링
- 브라이틱스데이터분석
- Brightics
- EDA
- 브라이틱스서포터즈
- Today
- Total
Database for Everything
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_데이터 전처리, EDA ② 본문
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_데이터 전처리, EDA ②
Yeenn 2021. 9. 13. 23:18
안녕하세요! Brightics 서포터즈 yeenn입니다.
이번 포스팅에서는 지난 포스팅 ↓ 에 이어
https://yeenn-db.tistory.com/31
[삼성 SDS Brightics] Brightics 개인 분석 프로젝트_서울시 골목상권 데이터분석_데이터 전처리①
안녕하세요! Brightics 서포터즈 yeenn입니다. ProDS시험도 끝났겠다 (합격도 했겠다!) 개강 첫 주라 비교적 여유로운 한 주를 보내고 있는데요, 정말 오랜만에 여유있게 포스팅을 작성하는 것 같아 기
yeenn-db.tistory.com
데이터 전처리 및 EDA과정을 다루어 보도록 하겠습니다!
Select Column으로 컬럼명 변경
Load한 15개의 dataset에는 모두 기준연도 코드와 기준 분기코드가 존재하는데요,
이 중 다른 데이터셋과 비교했을 때, 상권-직장인구 데이터만 기준연도변수의 컬럼명이 달라
이후 bind 작업을 위해 미리 연도명을 통일해주었습니다.

기준_년월_코드 → 기준_년_코드
로 컬럼명을 변경해주었습니다.
Random Sampling 통해 랜덤 변수 추출

그 다음은, Random sampling함수를 통해 랜덤 변수를 추출했습니다.
Number: 6000
seed값: 1234 고정으로 두고
모든 Load된 data에 동일하게 함수를 적용했는데요,
우선 Random Sampling을 사용한 이유는..
데이터셋마다 수집된 데이터의 개수가 다 달랐고,
일부 데이터 셋의 경우 데이터의 개수가 너무 많아 통일하여 분석하기가 어려운 상황이 되었습니다.
EDA를 위해 table을 시각화할 때도, brightics에서 육안으로 확인이 되는 row의 개수는 50,000개였기 때문에, table에 표시되지 않은 50,000개 이상의 데이터들은 시각화하여 표현하기가 힘들더라구요..!
각 데이터셋의 최소 데이터 개수가 약 6200개인 것으로 확인되었고, 이에 맞추어
각 변수의 최소 row 개수 반영한 샘플링 개수인 6000개를 Number로 설정했습니다!

랜덤 샘플링을 마친 상권-추정매출 데이터의 모습입니다!
<상권-추정매출(2019&2020) EDA>
[(서울 열린데이터 광장) 서울시 골목상권 데이터의 상권-추정매출 정보]
추정매출은 3개의 카드사(BC/KB/SH)의 카드승인금액을 기반으로 서울시의 보정비율을 곱하여 100개 생활밀접업종 매출액을 추정한 금액입니다.
(추정매출액 = 카드승인금액 / 보정비율)
2018년도까지는 위와같은 카드사의 데이터를 사용했으나, 2019년부터는 신한카드사의 카드승인금액만을 기반으로 매출을 추정하고 있어 매출 양상이 다르게 나타날 수 있습니다.
총 매출 금액 파생변수 생성

변수를 살펴보니, 총 매출 금액과 관련한 변수가 존재하지 않았는데요,
이후 분석과정에 꼭 필요한 중요한 변수라고 판단되었기 때문에, 파생변수를 생성해 주었습니다.
총 매출 금액은
-주중매출 금액 + 주말 매출 금액
-sum(월-일 매출금액)
두 식 모두로 같은 결과를 얻을 수 있지만,
계산의 편의를 위해 주중매출금액과 주말매출의 금액을 합하여
Add function Column 기능을 사용하여 총_매출_금액 변수를 생성했습니다!
[분기/연도별 상권_추정매출]

[분기/연도별 상권배후지_추정매출]

조금 특이점이 있었다면,
상권매출액의 경우, 매출 금액의 합이 2019년보다 2020년이 더 많은 것으로 확인된 반면, 상권 배후지의 매출액의 경우, 매출 금액의 합이 2029년보다 2019년이 더 많은 것으로 확인되었습니다.
2020년 2월부터 코로나 첫 확진자가 발생했는데, 상권 배후지와 상권 매출액 간 연도별 매출액 차이가 상이하게 나타나는 이유가 무엇인지는, 이후 회귀분석 과정 등을 통해 조금 더 자세히 살펴보도록 하겠습니다!
[상권-골목상권, 발달상권, 전통시장, 관광특구 정의]
서울시 골목상권 데이터의 상권 구분은 아래와 같이 이루어집니다.
*골목상권: 골목상권중 점포 밀집도가 높은 상권으로 총 1,010개 골목상권

*발달상권: 유통산업발전법 제5조의 법조항에 따라 2천 제곱미터 이내 50개 이상의 상점이 분포하는 경우 “상점가”라 하고, 배후지를 고려하지 않은 도보이동이 가능한 범위내의 상가업소밀집지역
(도매・소매・음식・숙박・생활서비스・금융・부동산・학문・교육・의료복지・문화예술종교・관광여가오락 등의 8개 업종대분류 점포가 밀집한 지구로 정의)

*전통시장: 오랜 기간에 걸쳐 일정한 지역에서 자연발생적으로 형성된 상설시장이나 정기시장

*관광특구: 관광활동이 주로 이루어지는 지역적 공간 內 입지한 상권

출처: https://golmok.seoul.go.kr/introduce3.do
우리마을가게 상권분석 서비스
제공정보 안내 업종과밀도 정의 : 사업체가 시장균형을 이룰 수 있는 적정한 정도를 넘어서 한 상권에 밀집하여 분포한 정도 구축내용 • 알고리즘 : 2013 - 2017년 상권정보 데이터를 활용한 GMM 모
golmok.seoul.go.kr
[상권별 총 매출 금액 / 총 매출 금액의 평균(위에서부터)]

위 그래프는 차례대로 상권별 총 매출 금액의 합과,
상권별 총 매출 금액의 평균을 시각화한 그래프입니다.
매출 금액의 합에서는, 골목상권 및 발달상권보다 관광특구가 더 적게 집계된 반면,
매출 금액의 평균에서는 골목상권 및 발달상권보다 관광특구의 매출액이 훨씬 더 큰것으로 분석되었는데요, 이는
관광특구의 경우 골목상권과 발달상권보다 매출이 발생하는 횟수나 빈도가 적지만, 관광인원이 몰리는 성수기의 경우, 평소 골목상권과 발달상권에서 발생하는 매출금액을 훨씬 웃도는 대규모의 매출액이 발생하기 때문일 것이라고 추정할 수 있었습니다!
[Unpivot 사용하여 Column형 data → Row형 data 변환]
[요일별 매출 금액]
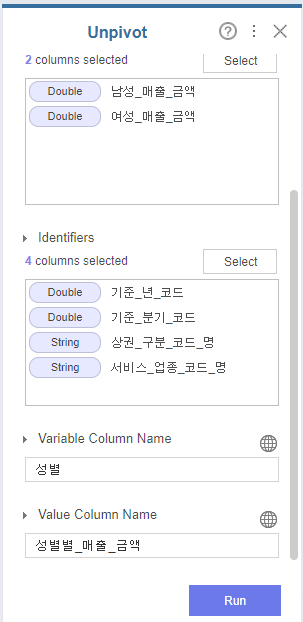
그 다음은, 상권의 요일별 매출 금액을 살펴보기 위해 Unpivot 함수를 사용해주었습니다.
Unpivot 함수는 Column형의 데이터를 Row형 데이터로 바꾸어주는 역할을 합니다!
데이터를 원하는 방향으로 정리하여 확인할 수 있다는 아주 큰 장점을 가지고 있는 기능이에요bb
지금처럼 변수가 많고, 변수 table이 복잡할 때 pivot과 unpivot 함수를 적절히 사용한다면 훨씬 데이터를 정리하기 편하답니다..!
월-일의 요일 데이터가 모두 Column형으로 정리되어있었기 때문에,
Unpivot을 불러와
Values에 월-금까지의 매출 금액 변수를 넣고,
Identifiers에 기준연도와 분기를 넣은 후,
Variable Column name: 요일
Value Column name: 요일별_매출_금액
으로 변수명을 설정해주었습니다.

왼쪽부터
금-목-수-월-일-토-화 요일 매출금액을 나타내는 점을 참고해주세요!
2019, 2020년 모두 일요일이 나머지 요일에 비해 매출이 적은 것을 확인할 수 있었는데요,
이는 일요일 휴무 영업장이 많기 때문이라는 이유를 추정할 수 있었습니다.
또, 2019년과 2020년 모두 금요일에 매출이 가장 많이 기록된 것을 확인할 수 있었습니다!
[요일, 상권별 매출금액]

그 다음은, 요일별, 상권별 매출금액을 시각화해보았습니다.
대체로 발달상권 > 골목상권 > 전통시장> 관광특구 순으로 매출액이 집계된 것으로 보입니다.
또, 미세한 차이는 있지만, 주말과 주중의 매출액 차이가 그렇게 크지 않은 골목상권, 전통시장, 관광특구와는 달리 발달상권의 경우, 주말과 주중의 차이, 특히 일요일과 나머지 요일의 매출액 차이가 상당함을 확인할 수 있었습니다.
[성별 별, 서비스 업종별 매출금액]
그 다음은, 성별별, 서비스 업종별 매출금액을 살펴보았습니다!
Values에 남성과 여성의 매출금액을 넣고,
Identifier에 서비스 업종코드명을 포함한 4개의 기준 변수를 넣어주었습니다.

가장 위로 높게 뻗어 있는 초록색 그래프는 한식 음식점인데요, 이 업종은 남성과 여성 모두 가장 높은 매출액을 기록한 업종입니다. 특히 남성의 경우, 가장 높은 매출액을 기록한 업종이기도 합니다.
여성의 경우, 갈색 그래프를 나타내는 일반 의원이 가장 높은 매출액을 기록한 것으로 분석되었습니다.
또,
가장 우측의 그래프인 화장품 업종과,
가운데의 적색 그래프인 의류 업종,
초록색 그래프 좌측의 베이지색 그래프인 편의점 업종에서
여성과 남성의 매출성향의 차이가 극명하게 드러남을 확인할 수 있었습니다.
[시간대별, 연도별 매출 금액]

마지막으로 살펴볼 그래프는, 시간대별, 연도별 매출금액입니다.
살펴봐야 할 점은,
코로나19가 발생하기 이전에는 14-17시의 매출액보다 17-21시의 매출액이 많았지만,
코로나 19가 발생한 이후인 2020년에는 14-17시의 매출액보다 17-21시의 매출액이 더 적다는 점인데요,
시간 제한이 동반된 거리두기 단계 조치의 적용으로 나타난 결과의 차이라고 생각이 되네요..!
이렇게 서울시 골목상권 데이터의 EDA까지 진행해봤는데요, 다음 포스팅에서는 조금 더 심화된 EDA와 나머지 전처리 작업을 추가적으로 진행해보도록 하겠습니다! :)
-본 게시물은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.



